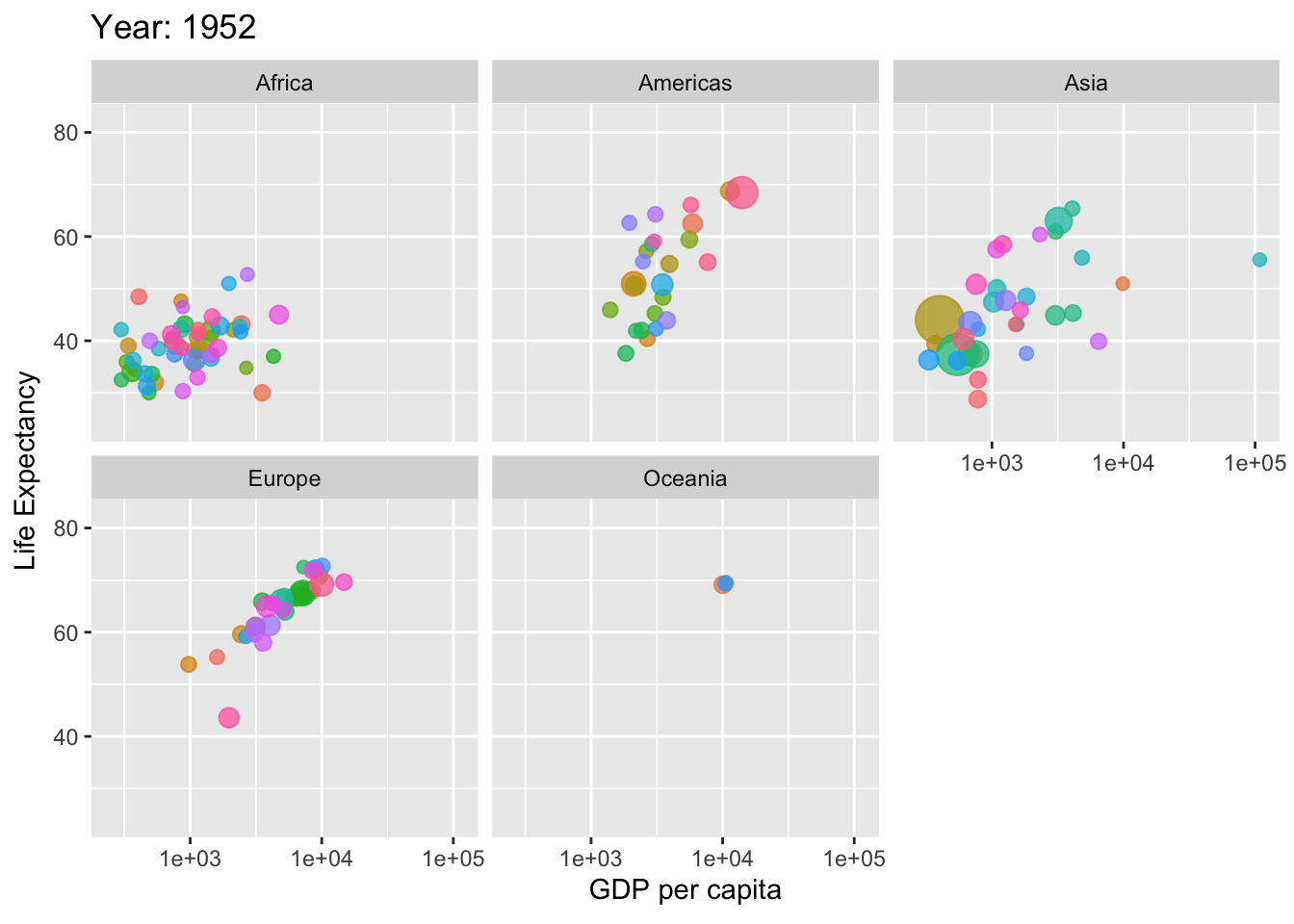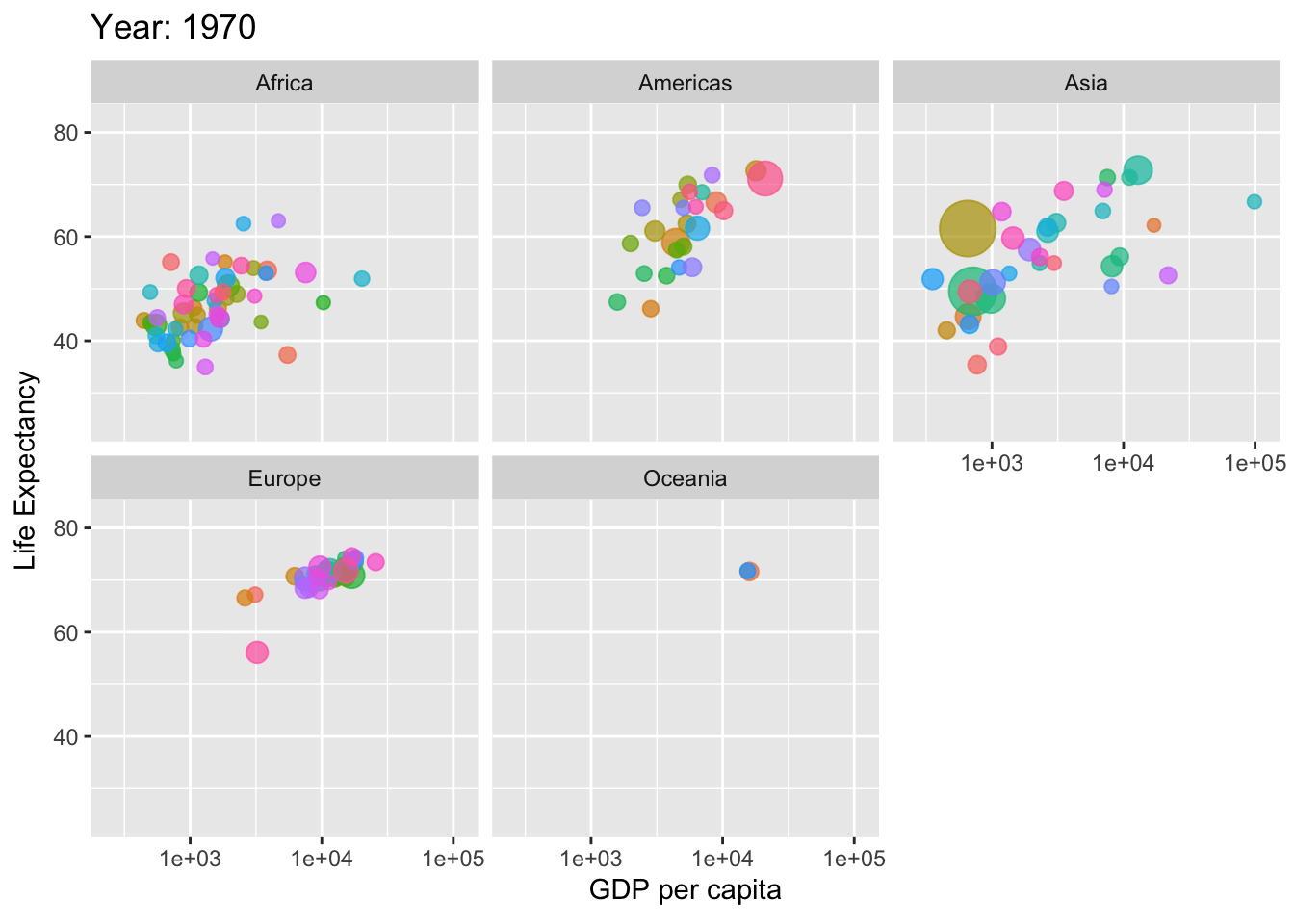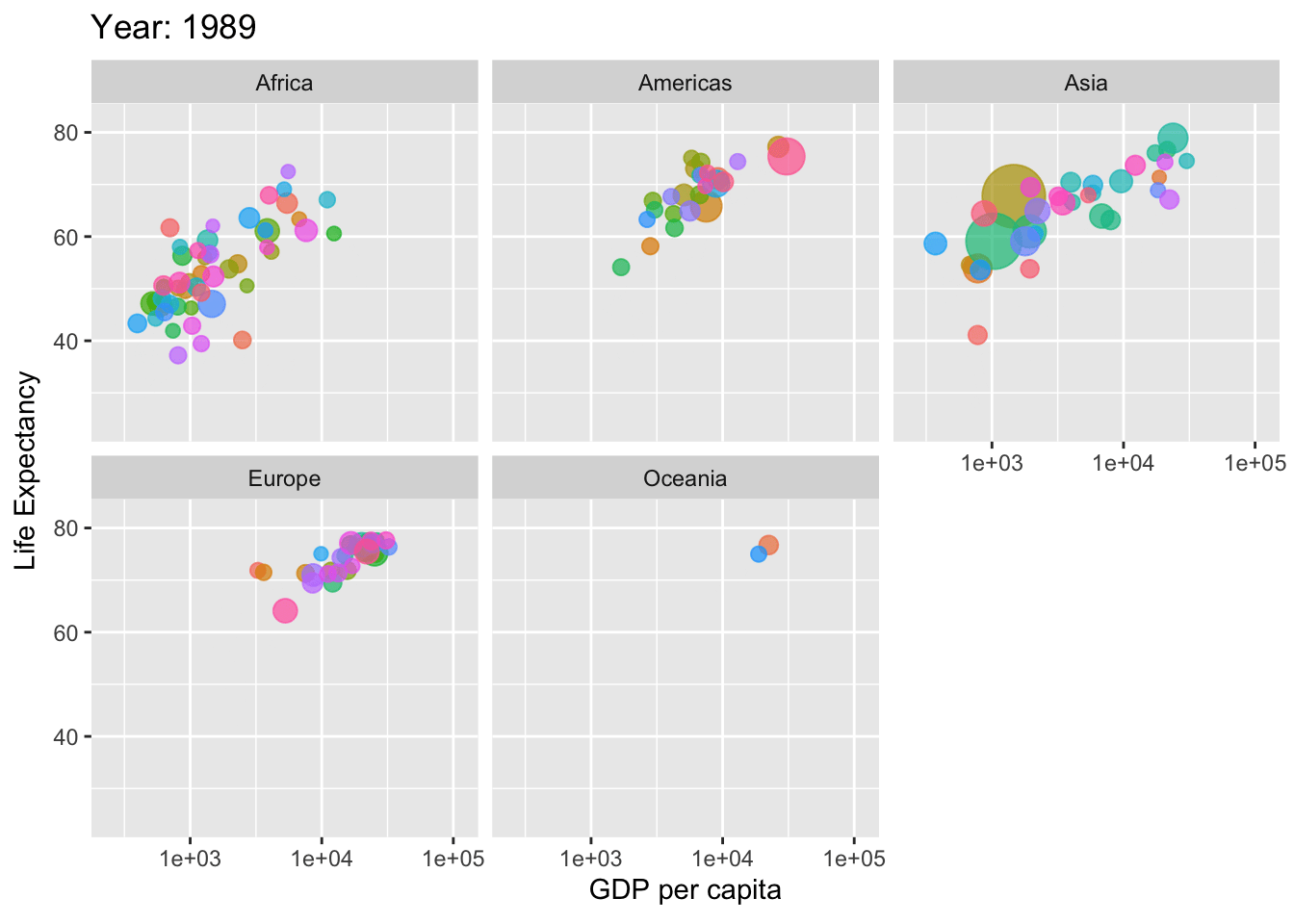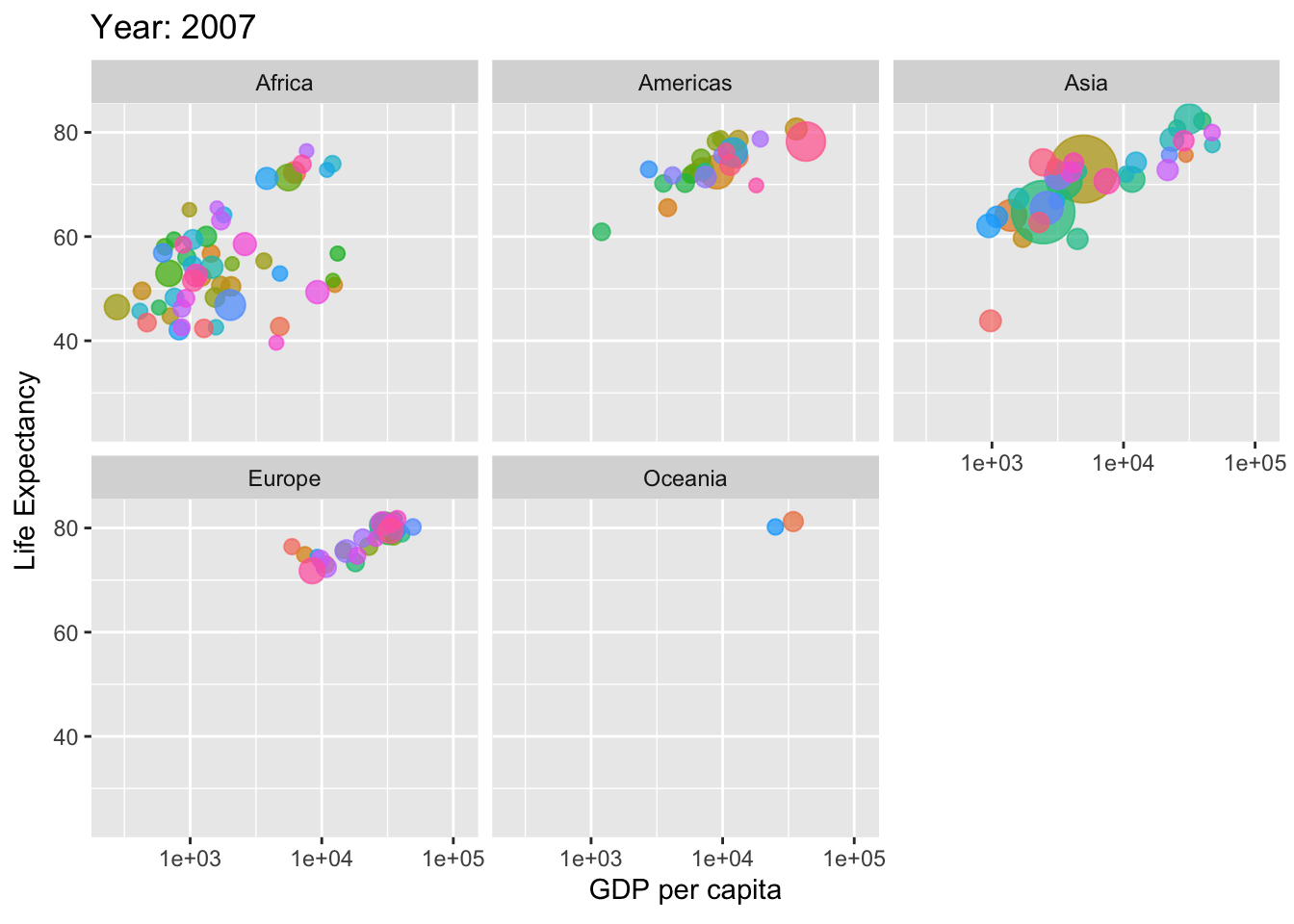
if(!require(ggplot2)) install.packages("ggplot2")if(!require(gifski)) install.packages("gifski") # For rendering the animation
Loading required package: gifski
library(gganimate)library(gapminder)library(ggplot2)library(gifski)# Define country_colors if not available# You can either define your own color mapping or use a default onecountry_colors <- scales::hue_pal()(length(unique(gapminder$country)))# Create the animationp <-ggplot(gapminder, aes(gdpPercap, lifeExp, size = pop, colour = country)) +geom_point(alpha =0.7, show.legend =FALSE) +scale_colour_manual(values = country_colors) +scale_size(range =c(2, 12)) +scale_x_log10() +facet_wrap(~continent) +labs(title ='Year: {frame_time}', x ='GDP per capita', y ='Life Expectancy') +transition_time(year) +ease_aes('linear')# Render the animationanimate(p, renderer =gifski_renderer())
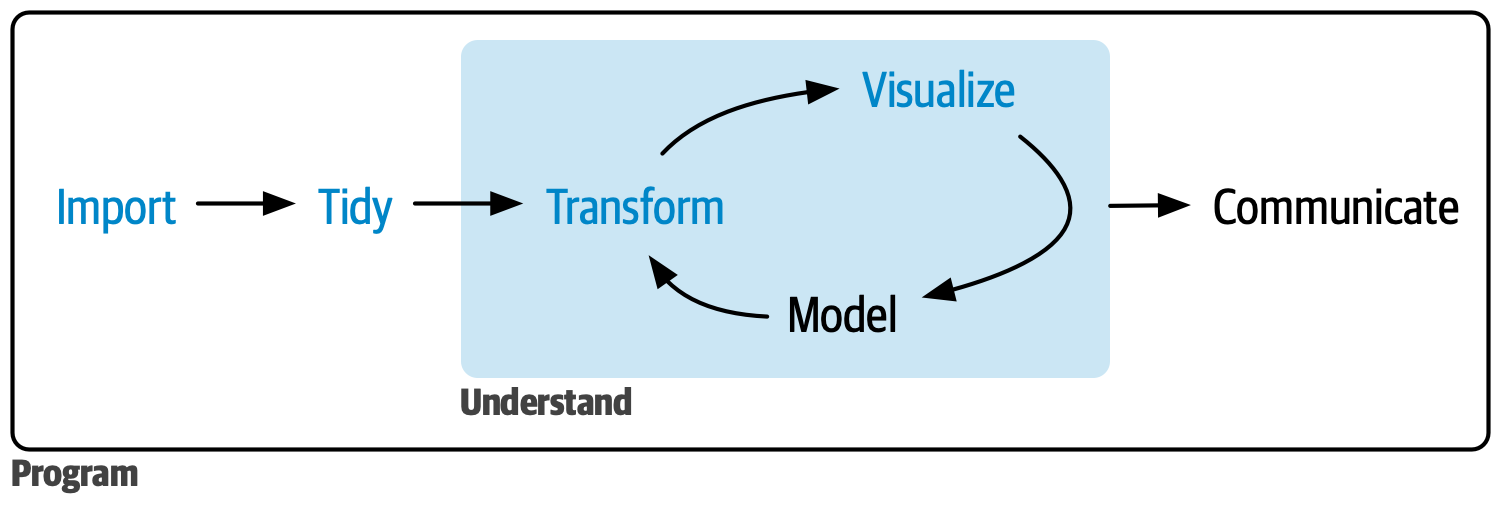
What is Data Science?
“An iterative process of augmenting human thinking with computational tools to use data to make decisions in/about the world”
It is recommended that object names be descriptive. Additionally, adopting a programming style for your data analysis is valuable. It facilitates human reading and interpretation of the code. Let’s look at object names from r4ds. Which one is better?
The tidyverse style guide: this guide not only presents good practices and programming style but is accompanied by two packages that help data scientists maintain code consistency.
Functions
Functions
Functions are the workhorse of statistical programming in R. Many of the analyses we will perform are based on using the correct functions and identifying the appropriate arguments for each case.
We have already seen some examples of functions:
install.packages() # installs packageslibrary() # loads packages into memoryrequire() # loads packages into memorysessionInfo() # information about the R version
The main use of functions is to automate operations that would take a long time to do manually, be prone to errors, or simply be tedious. For this reason, functions are developed in packages.
Functions
For example, if we need to find the mean between two numbers, we could do the calculation manually:
(35+65) /2
But if we had 1000 numbers instead of 2, this process would be extremely long and tiring. So, we can simply use the mean() function to calculate the average of all numbers from 1 to 1000:
mean(1:1000)
Functions
R has countless functions for doing all kinds of calculations that you can imagine (and even those you can’t). As you progress in using R, there will be specific tasks for which no existing function is satisfactory. In these moments, the advantage of R being a programming language becomes evident — we can create our own functions.
For now, let’s explore some of the functions that already exist in R. Did you notice that I didn’t need to type all the numbers from 1 to 1000 in the previous example?
numbers <-1:1000numbers_desc <-1000:1
Much easier than numbers <- c(1, 2, 3, ..., 1000).
Functions
But what if I wanted to find the mean of the odd numbers from 1 to 1000? Would I need to type the numbers one by one?
In these moments, remember that laziness is one of the traits that separates good programmers from the rest. Almost all tedious and repetitive tasks in programming can be automated in some way.
Obviously, R has the seq() function that allows us to create a vector of odd numbers. Notice how the arguments of the function are used:
odds <-seq(from =1, to =1000, by =2)mean(odds)
Functions
R comes pre-installed with several statistical functions — after all, this is one of its main purposes. Besides the mean() function, which we saw earlier, let’s also look at other descriptive statistics:
sd(odds) # standard deviationvar(odds) # variancerange(odds) # rangeIQR(odds) # interquartile range
The summary() command gives us an overview of this vector:
summary(odds)
Data Types
Data Types
Programming languages store variables under different classes. Today, we will have a general discussion about them so that you know they exist, and we will go into details throughout the course.
Numeric values: double, integer
Text: character
Factors: factor
Logical values: logical
Special values: NA, NULL, Inf, NaN
To discover the type of an object, you can use the typeof() function.
Dataframes
Dataframes
We can think of dataframes as collections of vectors placed side by side. It is by far the most used format for data analysis and processing.
names <-c("Mary", "Davi", "Juliana", "Gabriel")major <-c("Engineering", "Political Science", "Business", "Economy")time_at_company <-c(3, 10, 10, 1)team <-data.frame(names, major, time_at_company)nrow(team) # number of rowsncol(team) # number of columnshead(team) # first observationssummary(team) # summary of data
R also supports other data structures like matrices and lists, which we will cover as needed.
Data Tidying
Observations in rows
Attributes in columns
Values in cells
Subsetting Vectors
The tools we will now see are used to “pinpoint” information stored in R’s memory. Returning to the vector of odd numbers we created earlier, suppose I want to know the value of the 287th element:
odds <-seq(from =1, to =1000, by =2)odds[287]
We can expand the [ operator for various selections, as needed:
odds[c(1, 76, 48)] # select various numbersodds[-c(1:250)] # all numbers except the first 250odds[odds >900] # only values greater than 900
Subsetting Dataframes
The use of the [ operator is similar for dataframes, but we need to pay attention to rows and columns:
team[1, 3] # row 1, column 3team[1,] # returns all of row 1team[, 3] # returns all of column 3team[, c(1, 3)] # returns columns 1 and 3
For dataframes, it is very common to use the $ operator to select columns:
team$time_at_company # selects the variable "time at company"team[, 3] # same result
Logical operators
Logical Operators
For more complex selections, it is common to rely on logical operators.
Logical
Logical Operators
The most common are & and |, but all relational operators are also recognized:
== (equal to)
!= (not equal to)
> (greater than)
< (less than)
>= (greater than or equal to)
<= (less than or equal to).
team[team$time_at_company ==10,] # only people with 10 years at the companyteam[team$time_at_company <5,] # only people with less than 5 years at the companyteam[team$time_at_company <5| team$major =="Business",] # less than 5 years at the company OR in and specific areateam[team$time_at_company >2& team$time_at_company <5,] # between 2 and 5 years at the company
Where to find Help?
Where to find Help?
The sum() function is often useful. It allows you to sum vectors. Let’s take the opportunity to consult the documentation of this function through another function, ?.
?sum()
Where to find Help?
Where to find Help?
Besides R’s official documentation, a very valuable resource is Stack Overflow.