
MGMT 47400: Predictive Analytics
Deep Learning
PyTorch vs. TensorFlow

Single Layer Neural Network
\[ \begin{align*} f(X) &= \beta_0 + \sum_{k=1}^{K} \beta_k h_k(X) \\ &= \beta_0 + \sum_{k=1}^{K} \beta_k g\left(w_{k0} + \sum_{j=1}^{p} w_{kj} X_j \right). \end{align*} \]
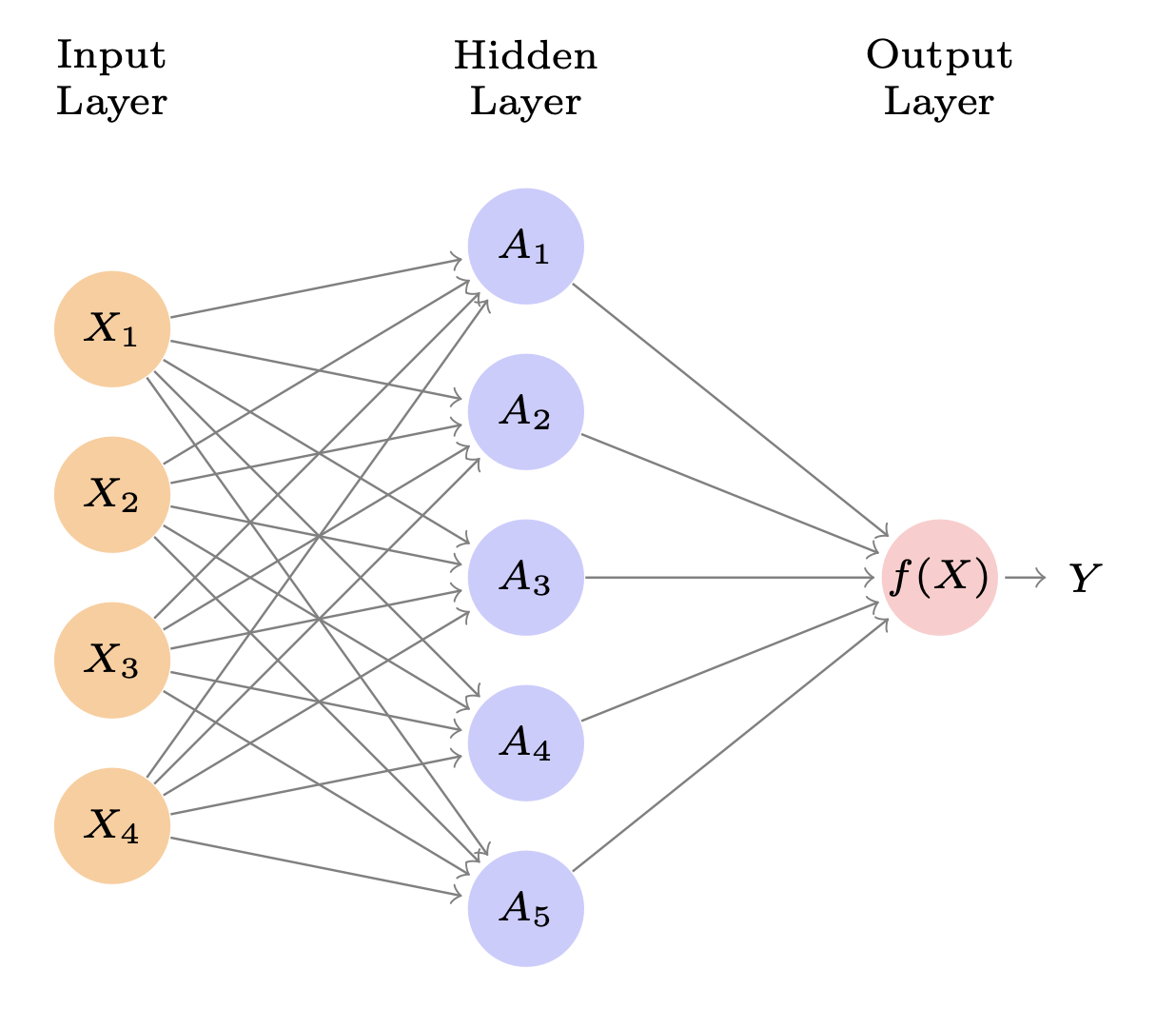
Network Diagram of Single Layer Neural Network
Single Layer Neural Network: Introduction and Layers Overview
\[ \begin{align*} f(X) &= \beta_0 + \sum_{k=1}^{K} \beta_k h_k(X) \\ &= \beta_0 + \sum_{k=1}^{K} \beta_k g\left(w_{k0} + \sum_{j=1}^{p} w_{kj} X_j \right). \end{align*} \]
Network Diagram of Single Layer Neural Network
Neural networks are often displayed using network diagrams, as shown in the figure.
- Input Layer (Orange Circles):
- \(X_1, X_2, X_3, X_4\)
- These are observed variables from the dataset.
- Hidden Layer (Blue Circles):
- \(A_1, A_2, A_3, A_4, A_5\)
- These are transformations (activations) computed from the inputs.
- Output Layer (Pink Circle):
- \(f(X) \to Y\)
- \(Y\) is also observed, e.g., a label or continuous response.
Single Layer Neural Network: Observed vs. Latent
\[ \begin{align*} f(X) &= \beta_0 + \sum_{k=1}^{K} \beta_k h_k(X) \\ &= \beta_0 + \sum_{k=1}^{K} \beta_k g\left(w_{k0} + \sum_{j=1}^{p} w_{kj} X_j \right). \end{align*} \]
Network Diagram of Single Layer Neural Network
Where is the observed data?
- \(X_j\) are observed (the input features).
- \(Y\) is observed (the response or label).
- The hidden units (\(A_k\)) are not observed; they’re learned transformations.
Single Layer Neural Network: Training the Network
\[ \begin{align*} f(X) &= \beta_0 + \sum_{k=1}^{K} \beta_k h_k(X) \\ &= \beta_0 + \sum_{k=1}^{K} \beta_k g\left(w_{k0} + \sum_{j=1}^{p} w_{kj} X_j \right). \end{align*} \]
Network Diagram of Single Layer Neural Network
The network learns all weights \(w_{kj}, w_{k0}, \beta_k, \beta_0\) during training.
Objective: predict \(Y\) from \(X\) accurately.
Key insight: Hidden layer learns useful transformations on the fly to help approximate the true function mapping \(X\) to \(Y\).
Single Layer Neural Network: Details
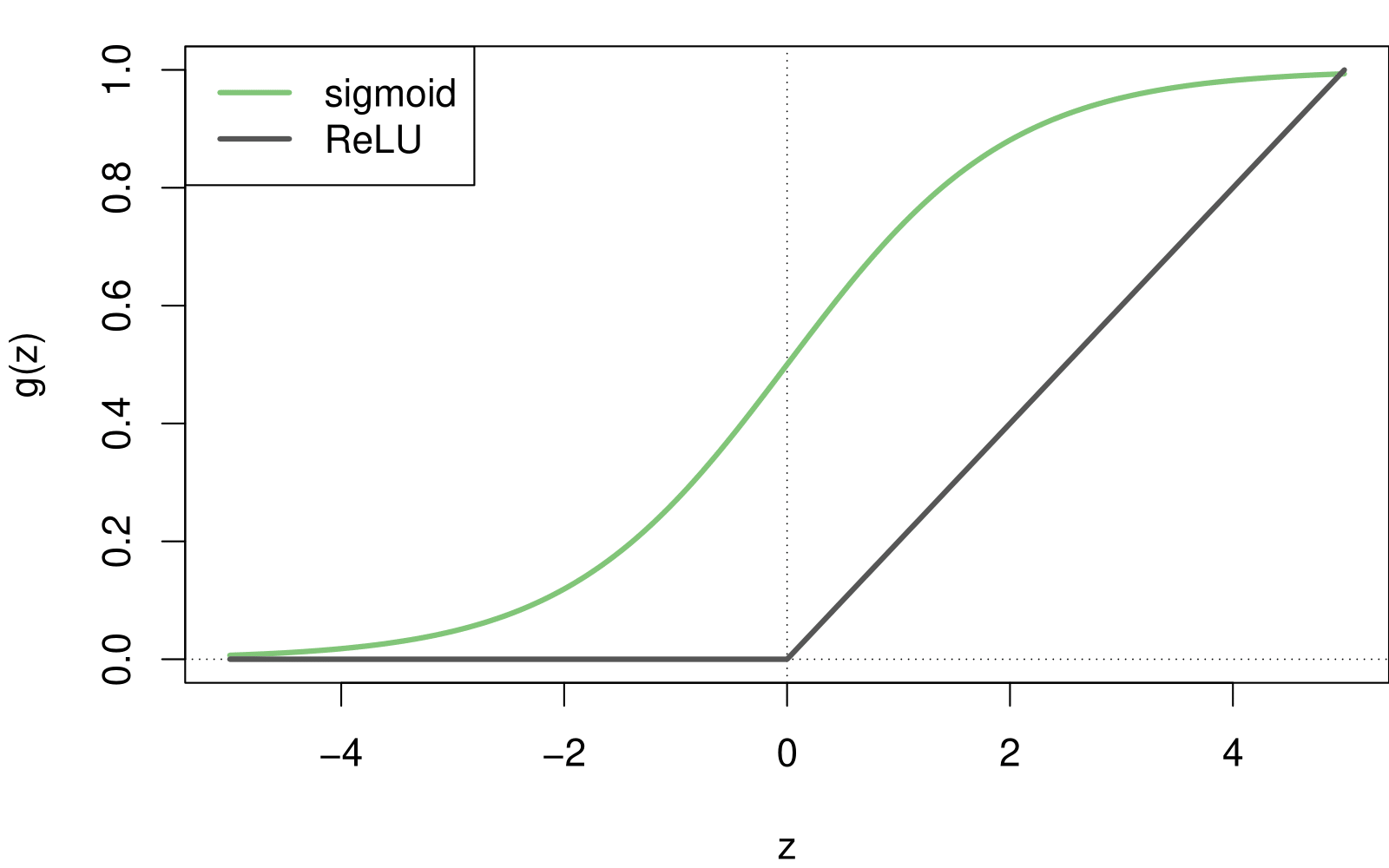
\(A_k = h_k(X) = g(w_{k0} + \sum_{j=1}^{p} w_{kj} X_j)\) are called the activations in the hidden layer. We can think of it as a non-linear tranformation of a linear function.
\(g(z)\) is called the activation function. Two popular activation functions are: the sigmoid and rectified linear (ReLU).
Activation functions in hidden layers are typically nonlinear; otherwise, the model collapses to a linear model.
So the activations are like derived features — nonlinear transformations of linear combinations of the features.
The model is fit by minimizing \(\sum_{i=1}^{n} (y_i - f(x_i))^2\) (e.g., for regression).
NN Example: MNIST Digits
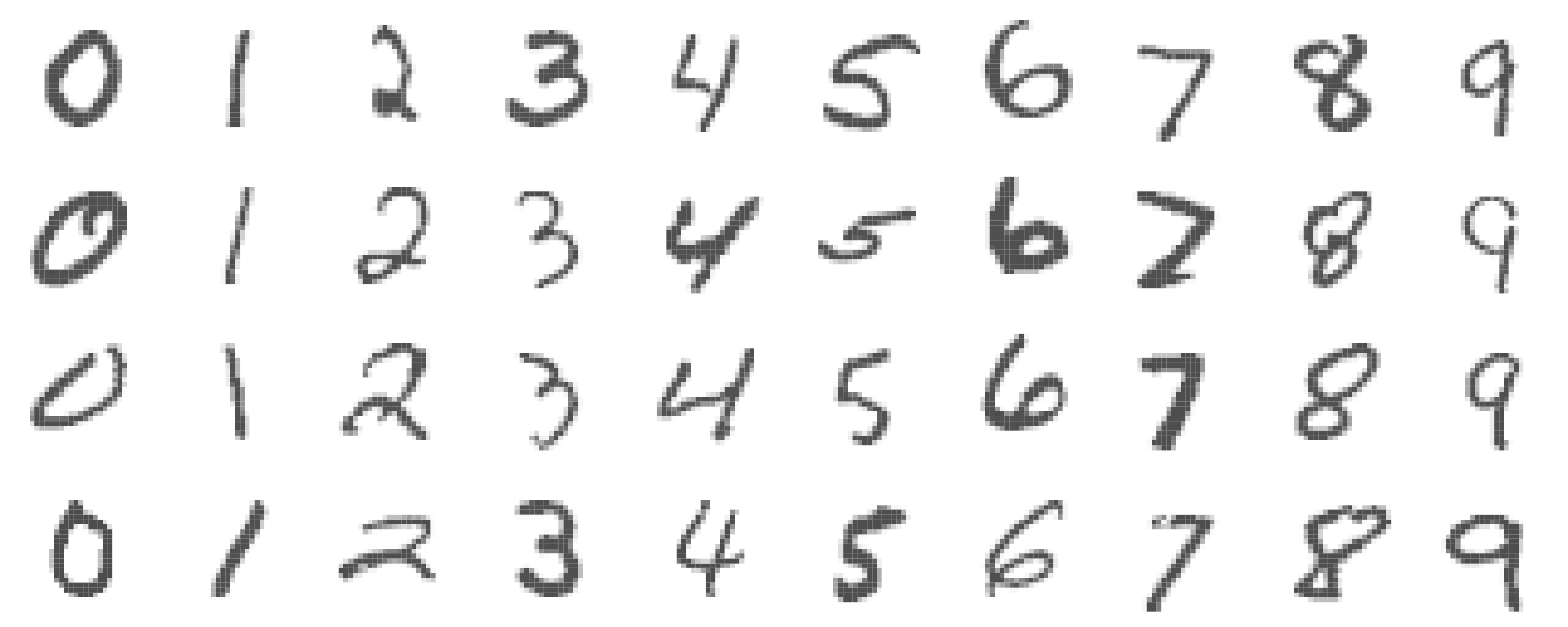

Handwritten digits
\(28 \times 28\) grayscale images
60K train, 10K test images
Features are the 784 pixel grayscale values \(\in (0, 255)\)
Labels are the digit class \(0\text{–}9\)
Goal: Build a classifier to predict the image class.
We build a two-layer network with:
256 units at the first layer,
128 units at the second layer, and
10 units at the output layer.
Along with intercepts (called biases), there are 235,146 parameters (referred to as weights).
Fitting Neural Networks
\[ \min_{\{w_k\}_{1}^K, \beta} \frac{1}{2} \sum_{i=1}^n \left(y_i - f(x_i)\right)^2, \quad \text{where} \]
\[ f(x_i) = \beta_0 + \sum_{k=1}^K \beta_k g\left(w_{k0} + \sum_{j=1}^p w_{kj} x_{ij}\right). \]
This problem is difficult because the objective is non-convex.
Despite this, effective algorithms have evolved that can optimize complex neural network problems efficiently.
Non Convex Functions and Gradient Descent
Let \(R(\theta) = \frac{1}{2} \sum_{i=1}^n (y_i - f_\theta(x_i))^2\) with \(\theta = (\{w_k\}_{1}^K, \beta)\).
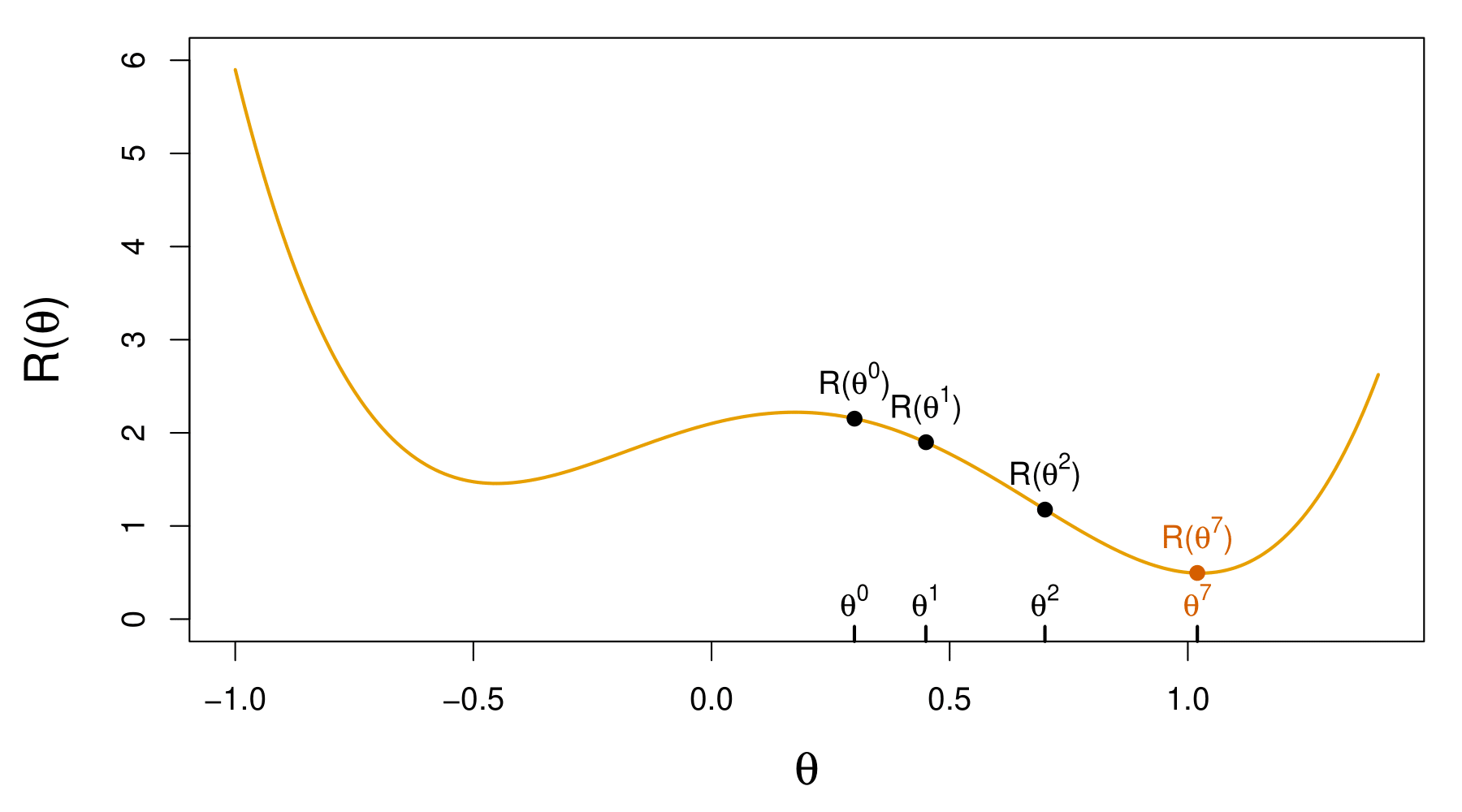
Start with a guess \(\theta^0\) for all the parameters in \(\theta\), and set \(t = 0\).
Iterate until the objective \(R(\theta)\) fails to decrease:
Find a vector \(\delta\) that reflects a small change in \(\theta\), such that \(\theta^{t+1} = \theta^t + \delta\) reduces the objective; i.e., \(R(\theta^{t+1}) < R(\theta^t)\).
Set \(t \gets t + 1\).
Dropout Learning

At each Stochastic Gradient Descent (SGD) update, randomly remove units with probability \(\phi\), and scale up the weights of those retained by \(1/(1-\phi)\) to compensate.
In simple scenarios like linear regression, a version of this process can be shown to be equivalent to ridge regularization.
As in ridge, the other units stand in for those temporarily removed, and their weights are drawn closer together.
Similar to randomly omitting variables when growing trees in random forests.
Ridge and Data Augmentation
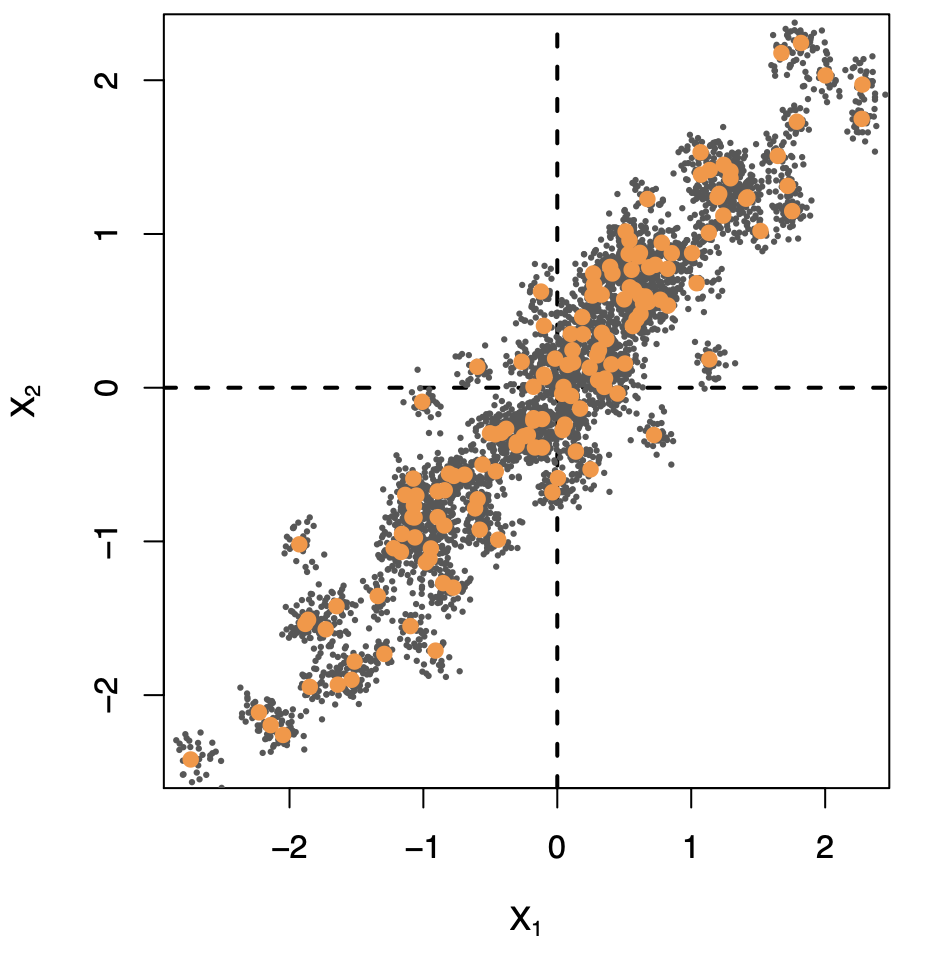
Make many copies of each \((x_i, y_i)\) and add a small amount of Gaussian noise to the \(x_i\) — a little cloud around each observation — but leave the copies of \(y_i\) alone!
This makes the fit robust to small perturbations in \(x_i\), and is equivalent to ridge regularization in an OLS setting.
Data Augmentation on the Fly

Data augmentation is especially effective with SGD, here demonstrated for a CNN and image classification.
Natural transformations are made of each training image when it is sampled by SGD, thus ultimately making a cloud of images around each original training image.
The label is left unchanged — in each case still tiger.
Improves performance of CNN and is similar to ridge.
The Double-Descent Error Curve
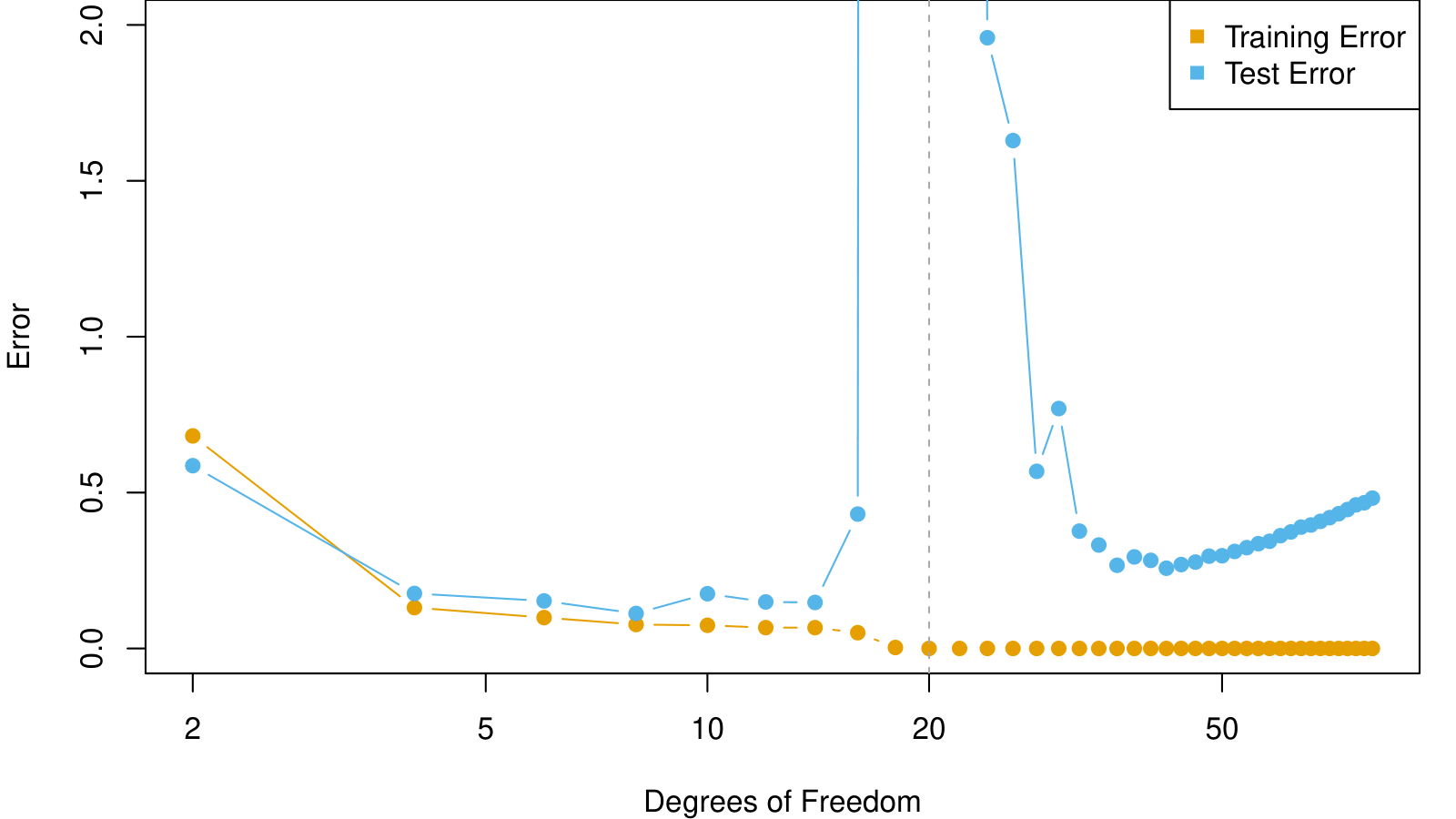
When \(d \leq 20\), model is OLS, and we see usual bias-variance trade-off.
When \(d > 20\), we revert to minimum-norm. As \(d\) increases above 20, \(\sum_{j=1}^d \hat{\beta}_j^2\) decreases since it is easier to achieve zero error, and hence less wiggly solutions.
Less Wiggly Solutions
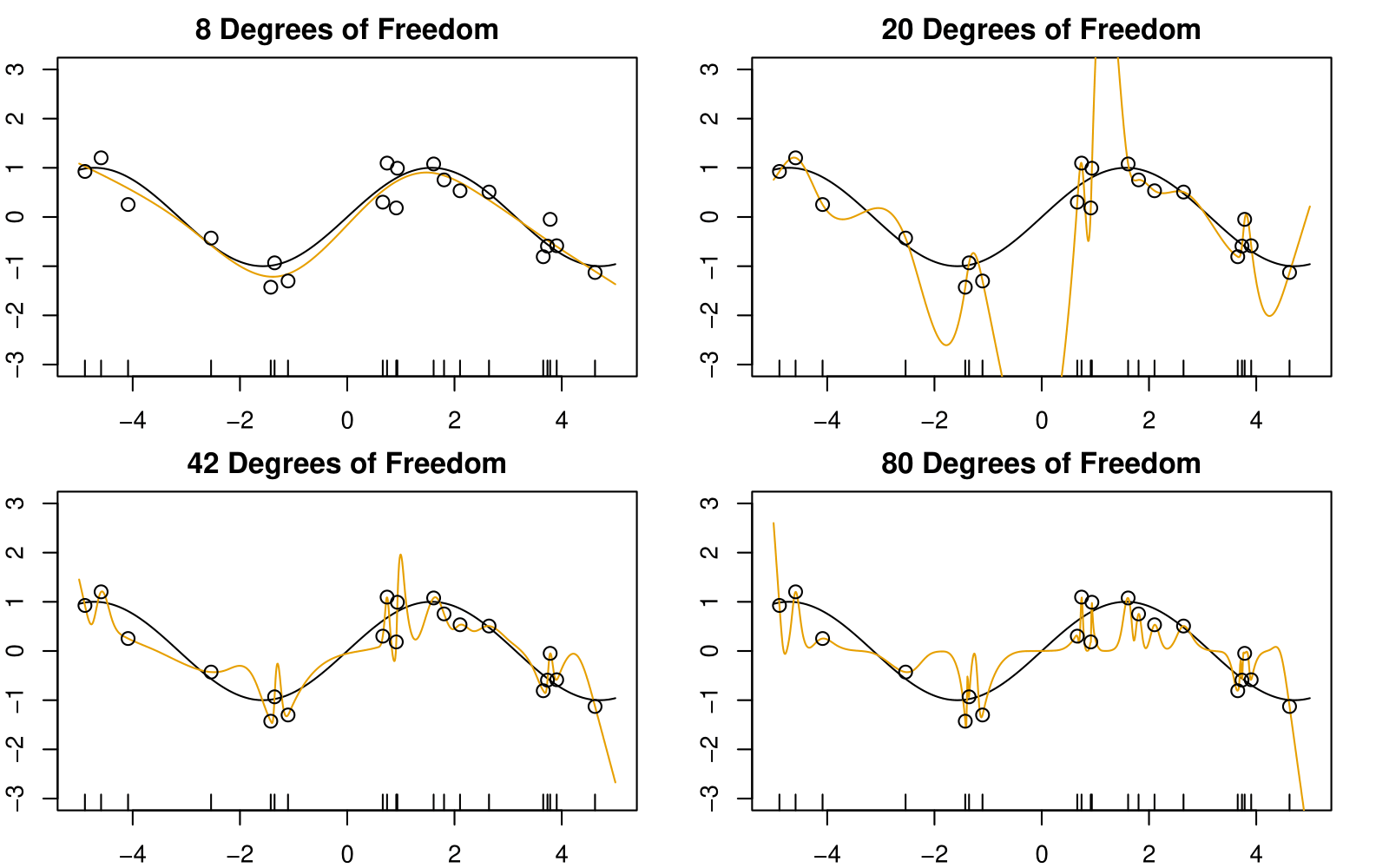
To achieve a zero-residual solution with \(d = 20\) is a real stretch!
Easier for larger \(d\).
The CIFAR100 Database

The figure shows 75 images drawn from the CIFAR100 database.
This database consists of 60,000 images labeled according to 20 superclasses (e.g. aquatic mammals), with five classes per superclass (beaver, dolphin, otter, seal, whale).
Each image has a resolution of 32 × 32 pixels, with three eight-bit numbers per pixel representing red, green, and blue. The numbers for each image are organized in a three-dimensional array called a feature map.
The first two axes are spatial (both 32-dimensional), and the third is the channel axis, representing the three (blue, green or red) colors.
There is a designated training set of 50,000 images, and a test set of 10,000.
The Convolutional Network Hierarchy
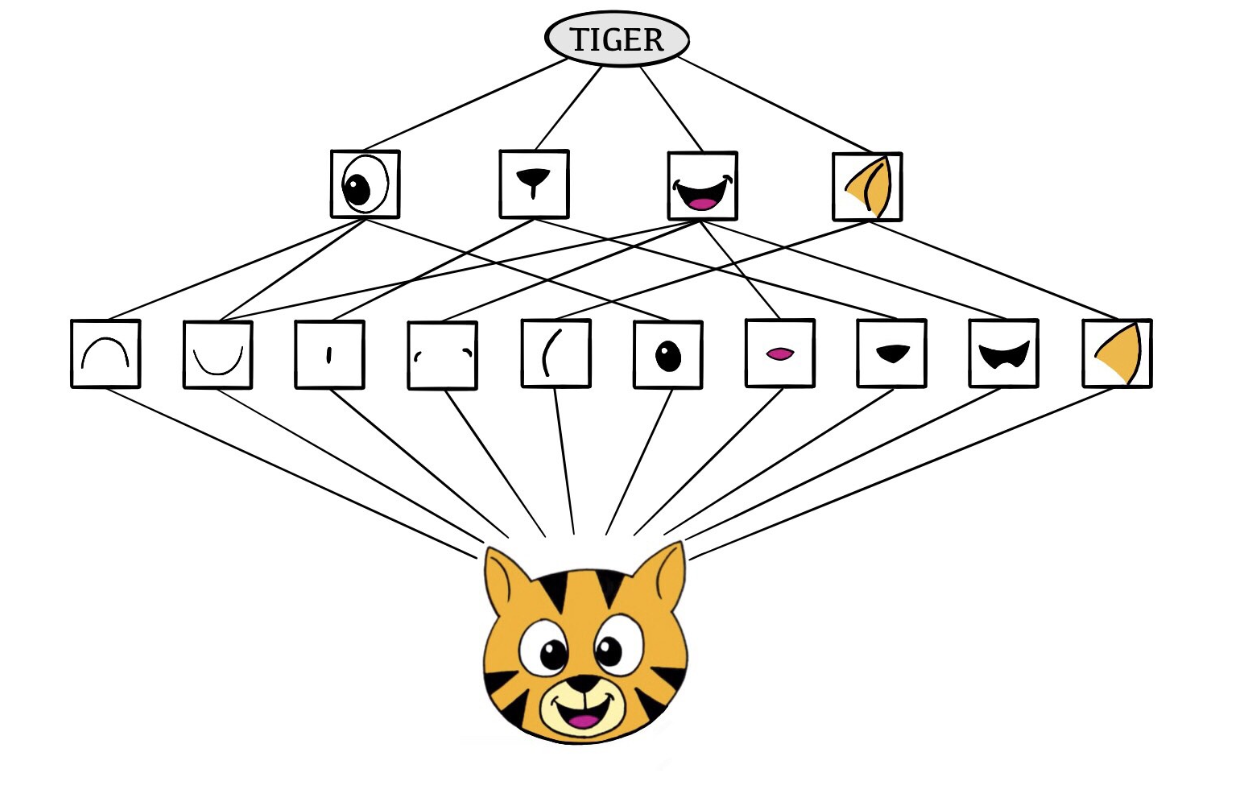
CNNs mimic, to some degree, how humans classify images, by recognizing specific features or patterns anywhere in the image that distinguish each particular object class.
The network first identifies low-level features in the input image, such as small edges or patches of color.
These low-level features are then combined to form higher-level features, such as parts of ears or eyes. Eventually, the presence or absence of these higher-level features contributes to the probability of any given output class.
This hierarchical construction is achieved by combining two specialized types of hidden layers: convolution layers and pooling layers:
Convolution layers search for instances of small patterns in the image.
Pooling layers downsample these results to select a prominent subset.
To achieve state-of-the-art results, contemporary neural network architectures often use many convolution and pooling layers.
Convolution Example

The idea of convolution with a filter is to find common patterns that occur in different parts of the image.
The two filters shown here highlight vertical and horizontal stripes.
The result of the convolution is a new feature map.
Since images have three color channels, the filter does as well: one filter per channel, and dot-products are summed.
The weights in the filters are learned by the network.
Architecture of a CNN
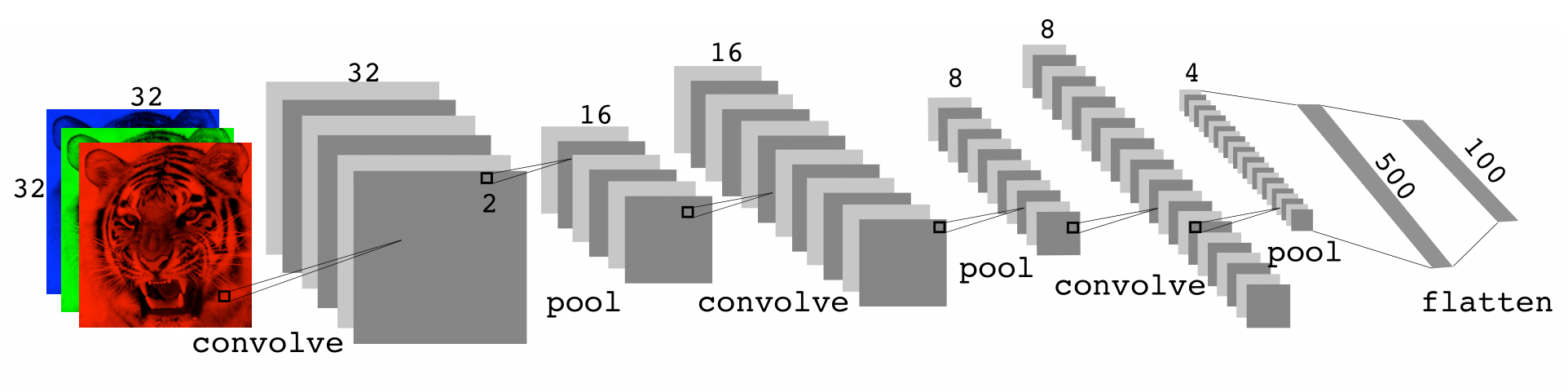
Many convolve + pool layers.
Filters are typically small, e.g., each channel \(3 \times 3\).
Each filter creates a new channel in the convolution layer.
As pooling reduces size, the number of filters/channels is typically increased.
Number of layers can be very large.
E.g., resnet50 trained on imagenet 1000-class image database has 50 layers!
Data Augmentation
An additional important trick used with image modeling is data augmentation.
Essentially, each training image is replicated many times, with each replicate randomly distorted in a natural way such that human recognition is unaffected.
Typical distortions are zoom, horizontal and vertical shift, shear, small rotations, and in this case horizontal flips.
At face value this is a way of increasing the training set considerably with somewhat different examples, and thus protects against overfitting.
In fact we can see this as a form of regularization: we build a cloud of images around each original image, all with the same label.
CNN Example: Pretrained Networks to Classify Images

Here we use the 50-layer resnet50 network trained on the 1000-class imagenet corpus to classify some photographs.
Document Classification Example: Lasso versus Neural Network — IMDB Reviews
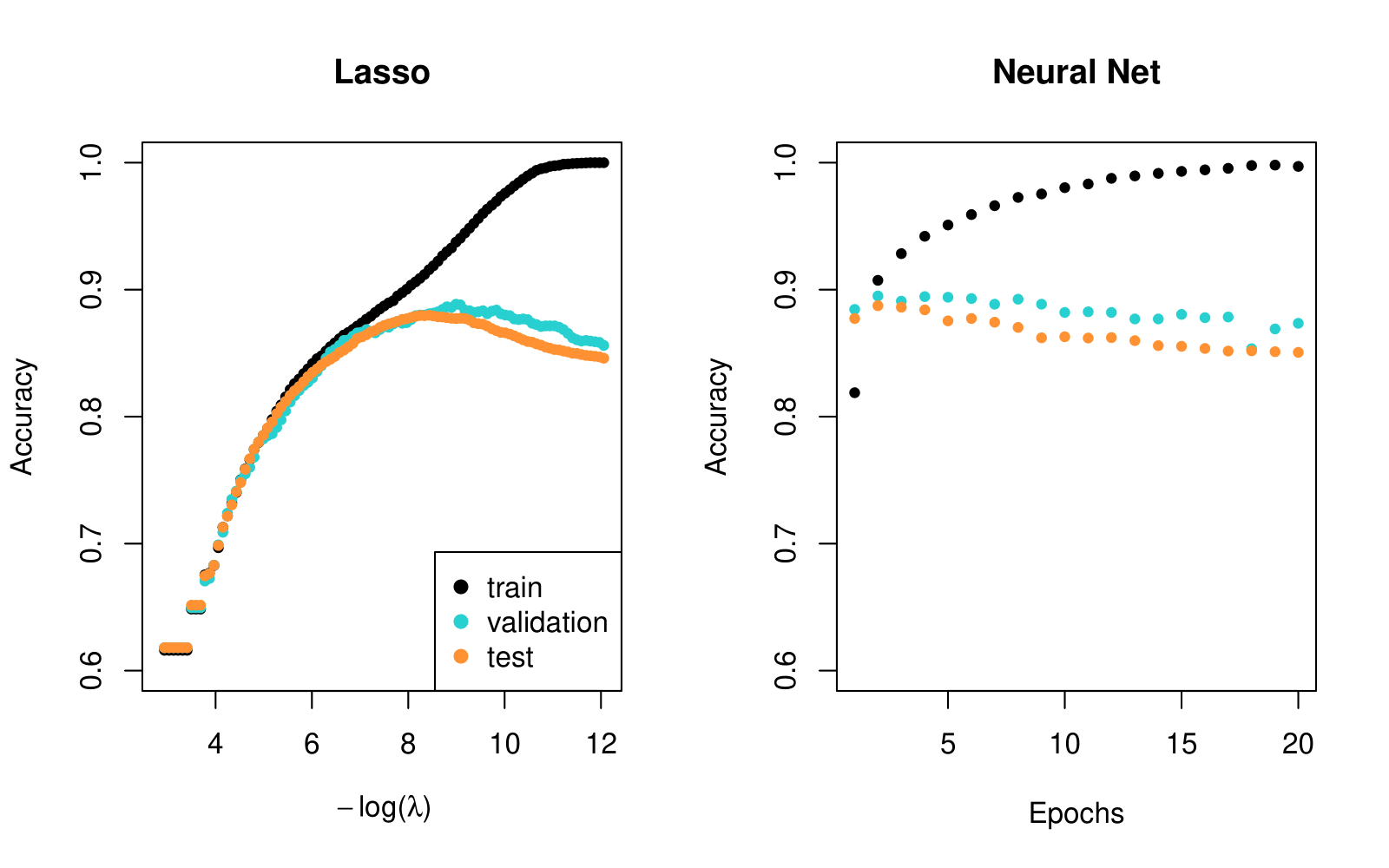
- Simpler lasso logistic regression model works as well as neural network in this case.
Simple Recurrent Neural Network Architecture
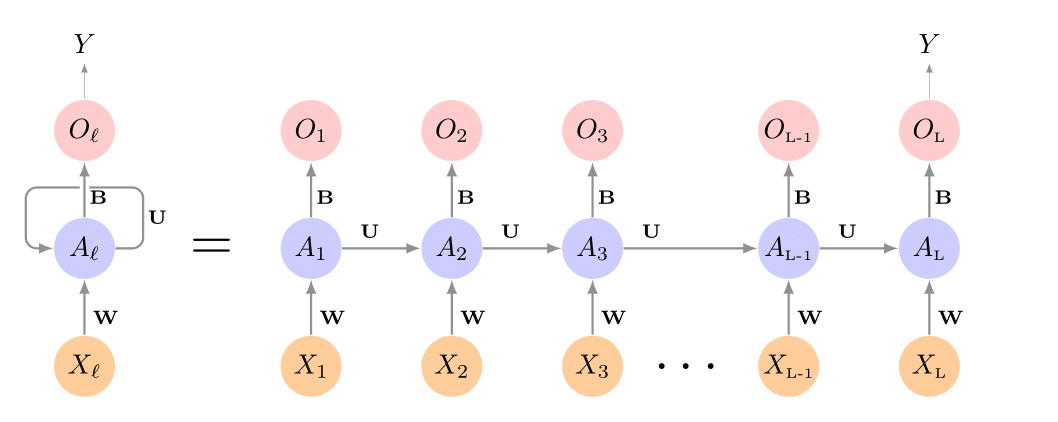
The hidden layer is a sequence of vectors \(A_\ell\), receiving as input \(X_\ell\) as well as \(A_{\ell-1}\). \(A_\ell\) produces an output \(O_\ell\).
The same weights \(\mathbf{W}\), \(\mathbf{U}\), and \(\mathbf{B}\) are used at each step in the sequence — hence the term recurrent.
The \(A_\ell\) sequence represents an evolving model for the response that is updated as each element \(X_\ell\) is processed.
Word Embedding - RNN Example: IMDB Reviews
Review:
this is one of the best films actually the best I have ever seen the film starts one fall day…
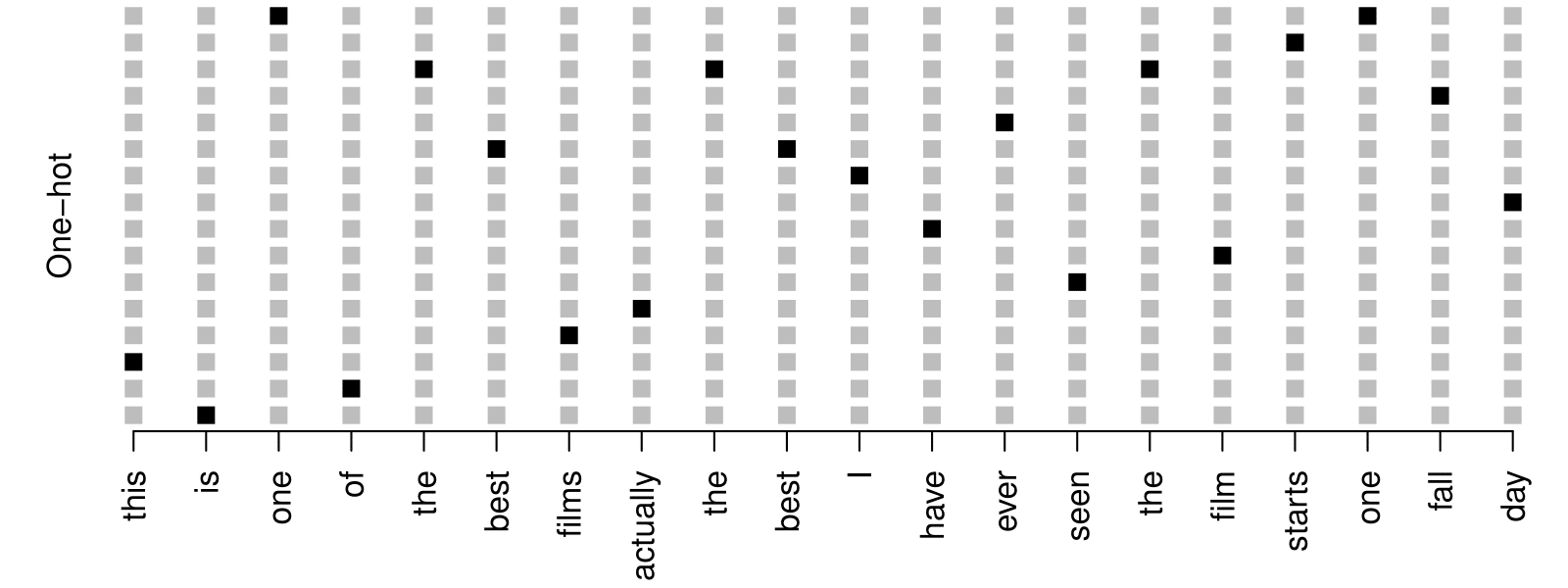

Embeddings are pretrained on very large corpora of documents, using methods similar to principal components. word2vec and GloVe are popular.
RNN: Time Series Forecasting
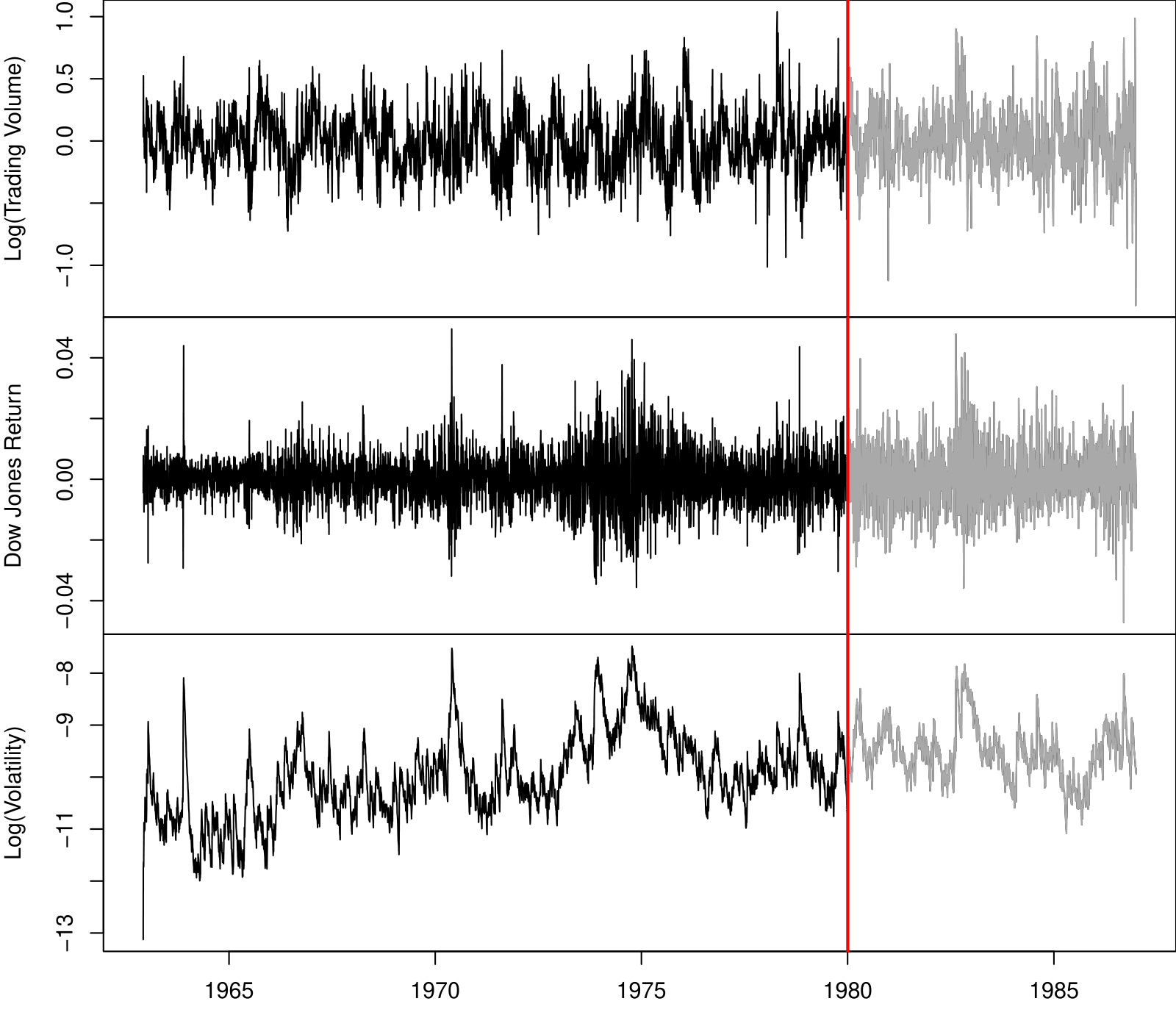
New-York Stock Exchange Data
Three daily time series for the period December 3, 1962, to December 31, 1986 (6,051 trading days):
Log trading volume. This is the fraction of all outstanding shares that are traded on that day, relative to a 100-day moving average of past turnover, on the log scale.
Dow Jones return. This is the difference between the log of the Dow Jones Industrial Index on consecutive trading days.
Log volatility. This is based on the absolute values of daily price movements.
Goal: predict Log trading volume tomorrow, given its observed values up to today, as well as those of Dow Jones return and Log volatility.
These data were assembled by LeBaron and Weigend (1998) IEEE Transactions on Neural Networks, 9(1): 213–220.
Autocorrelation
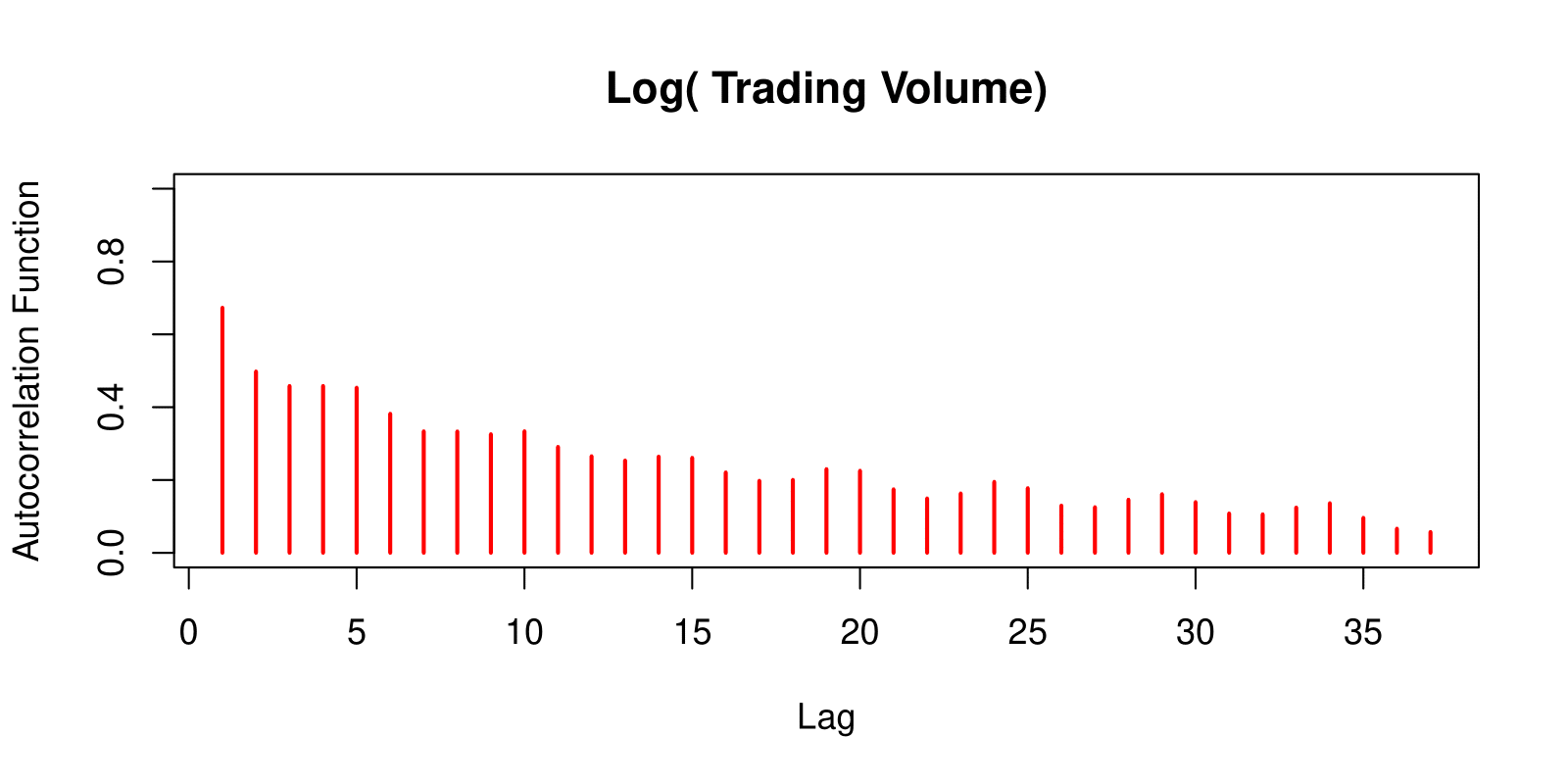
The autocorrelation at lag \(\ell\) is the correlation of all pairs \((v_t, v_{t-\ell})\) that are \(\ell\) trading days apart.
These sizable correlations give us confidence that past values will be helpful in predicting the future.
This is a curious prediction problem: the response \(v_t\) is also a feature \(v_{t-\ell}\)!
RNN Results for NYSE Data
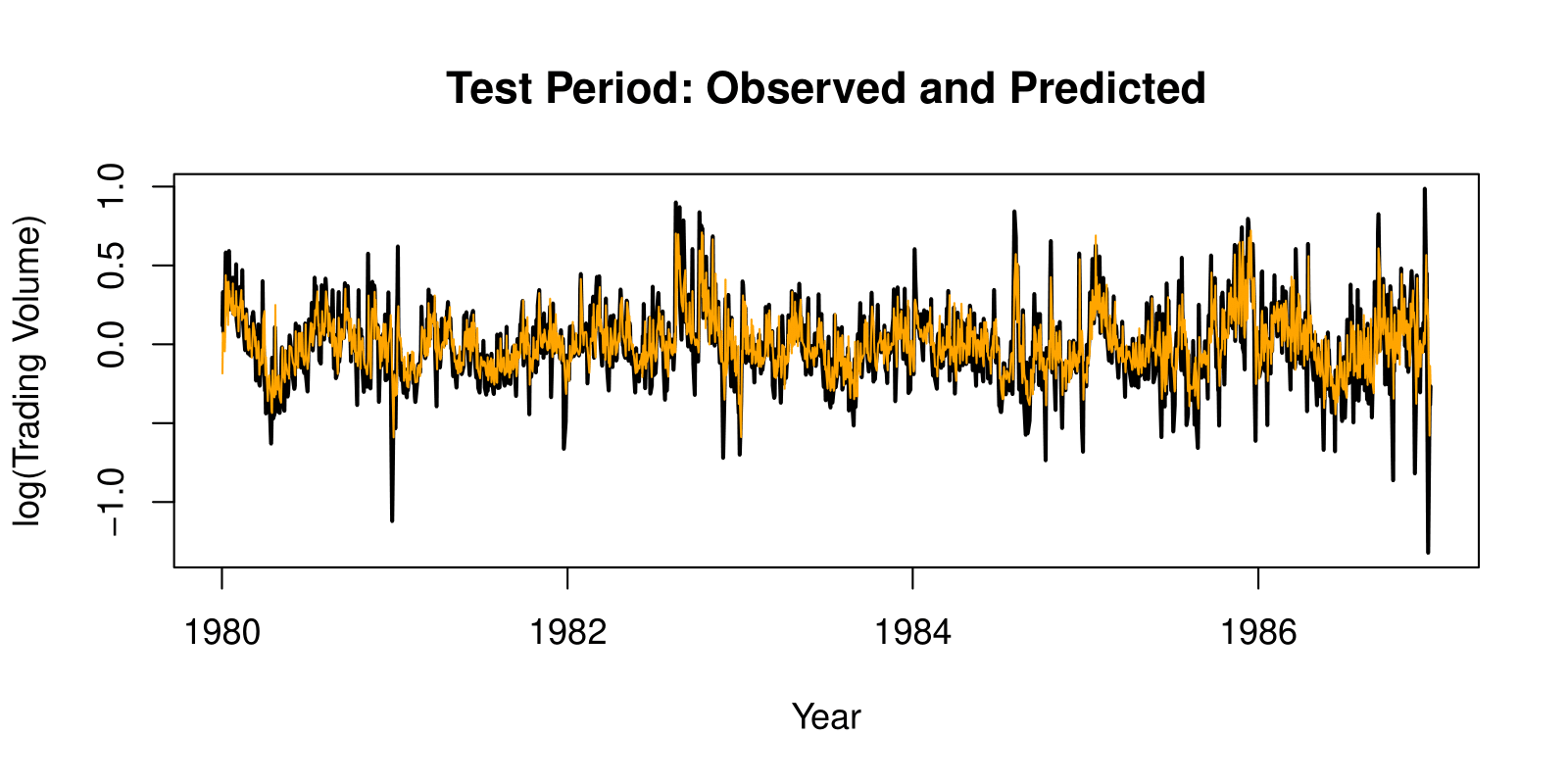
The figure shows predictions and truth for the test period.
\[ R^2 = 0.42 \text{ for RNN} \]
\(R^2 = 0.18\) for the naive approach — uses yesterday’s value of Log trading volume to predict that of today.
Flexibility vs. Interpretability
Trade-offs between flexibility and interpretability:
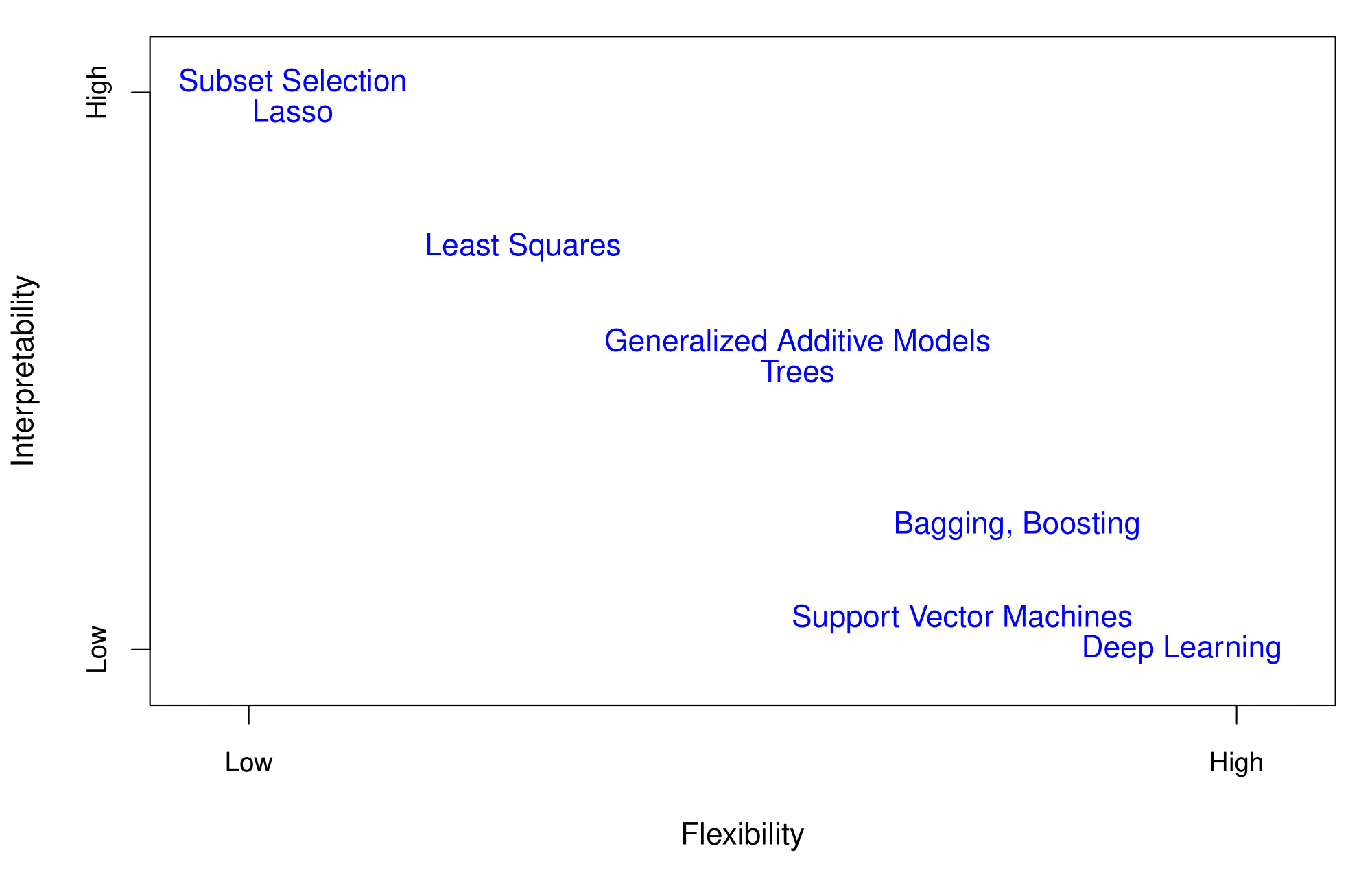
As the authors suggest, I also endorse the Occam’s razor principle — we prefer simpler models if they work as well. More interpretable!