MGMT 47400: Predictive Analytics
Beyond Linearity
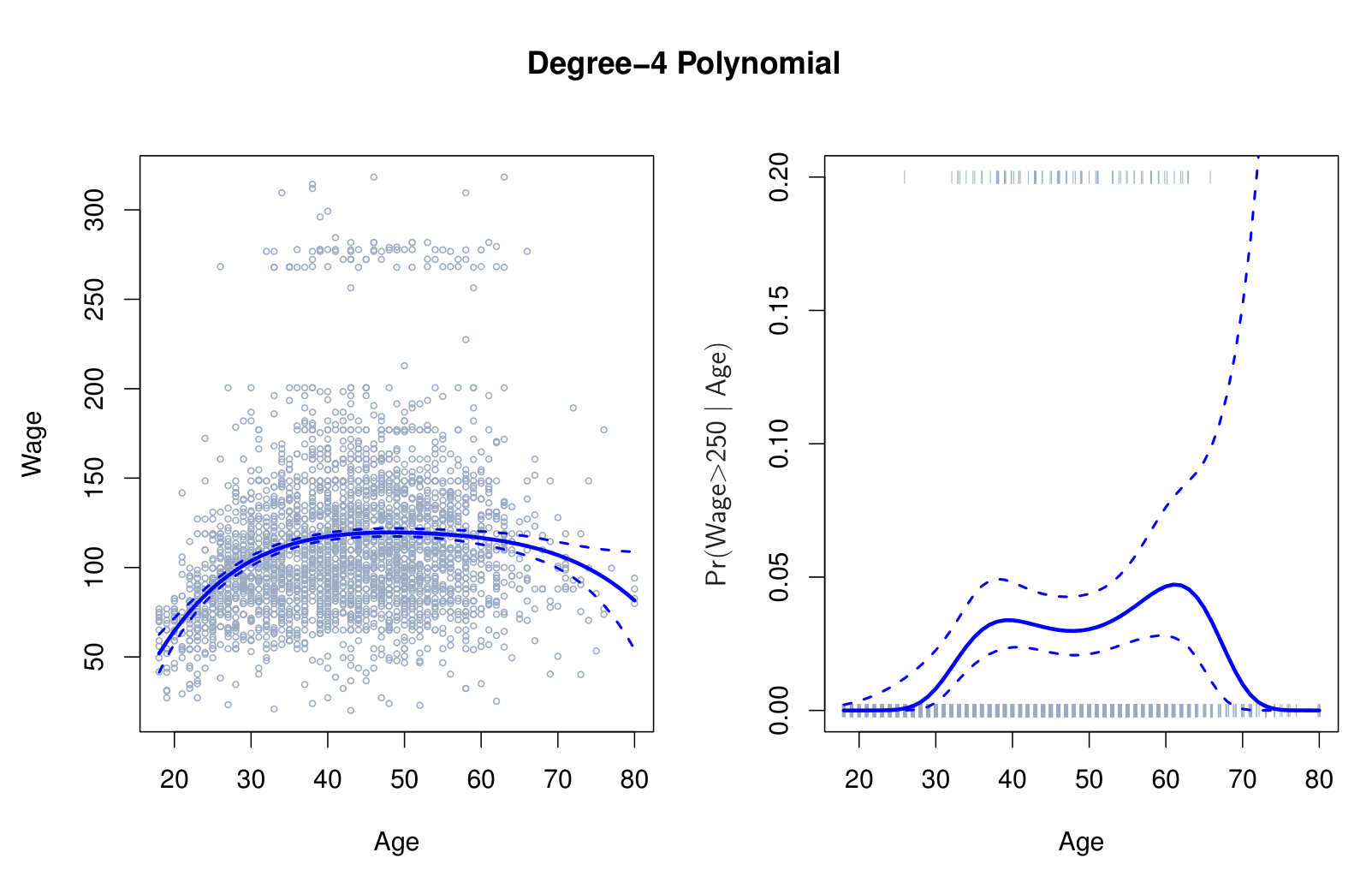
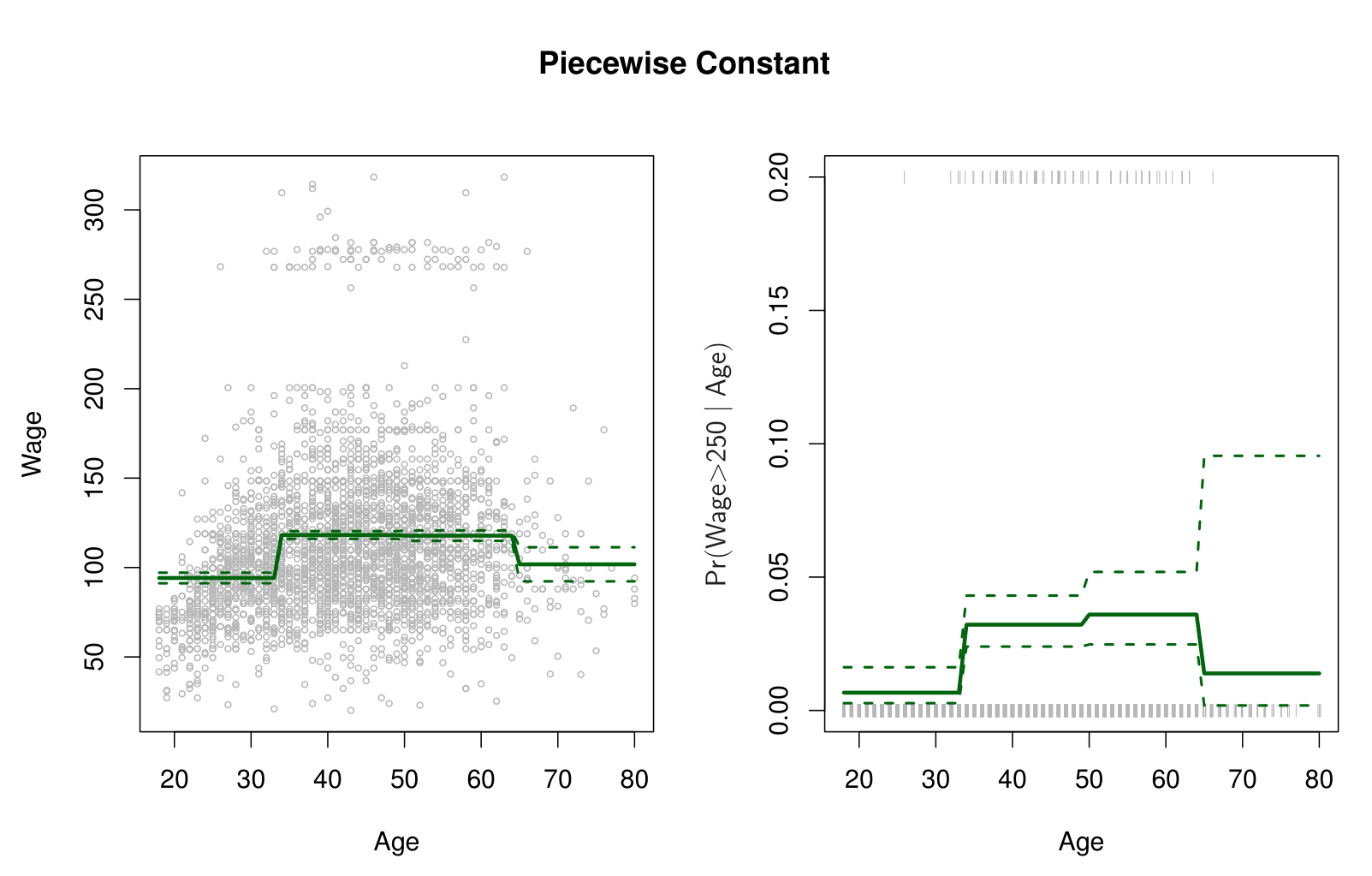
Step Functions
Step functions cut the range of a variable into \(K\) distinct regions in order to produce a qualitative variable. This has the effect of fitting a piecewise constant function.
\[ C_1(X) = I(X < 35), \quad C_2(X) = I(35 \leq X < 50), \dots, C_3(X) = I(X \geq 65) \]
Splines Visualization
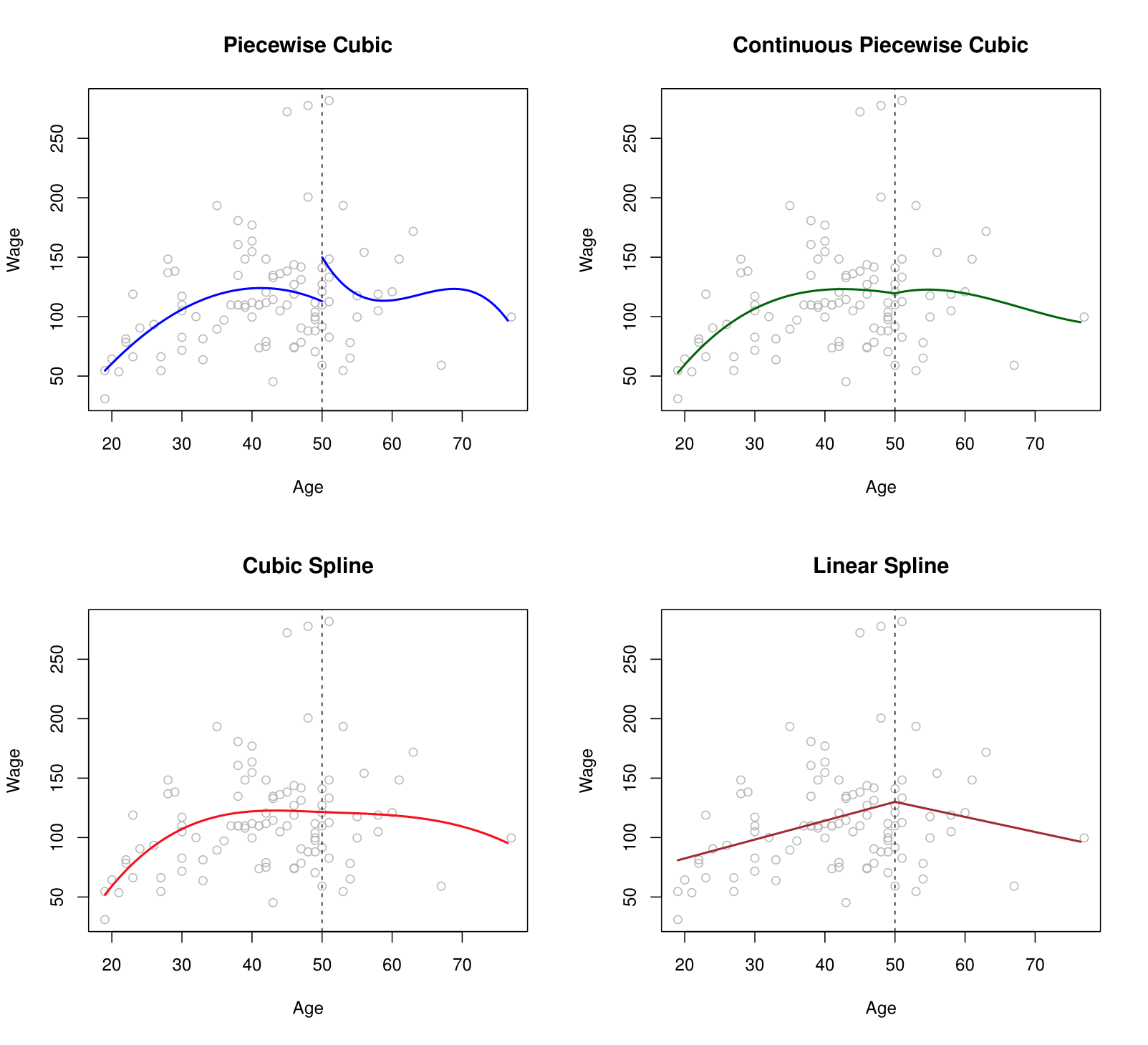
Top-Left Panel: A third-degree polynomial is fitted to the data on the left side of the knot at \(X = 50\), and another (separate) third-degree polynomial is fitted on the right side. There is no continuity constraint imposed at the knot, meaning the two polynomials may not meet at the same function value at \(X = 50\).
Top-Right Panel: Again, a third-degree polynomial is fitted on each side of \(X = 50\). However, in this case, the polynomials are forced to be continuous at the knot. In other words, they must share the same function value at \(X = 50\).
Bottom-Left Panel: As in the top-right panel, a third-degree polynomial is fitted on each side of \(X = 50\), but with an additional constraint that enforces continuity of the first and second derivatives at \(X = 50\). This ensures a smoother transition between the left and right segments of the piecewise function.
Bottom-Right Panel: A linear regression model is fitted on each side of \(X = 50\). The model is constrained to be continuous at the knot, so both linear segments meet at the same value at \(X = 50\).
Linear Splines Visualization
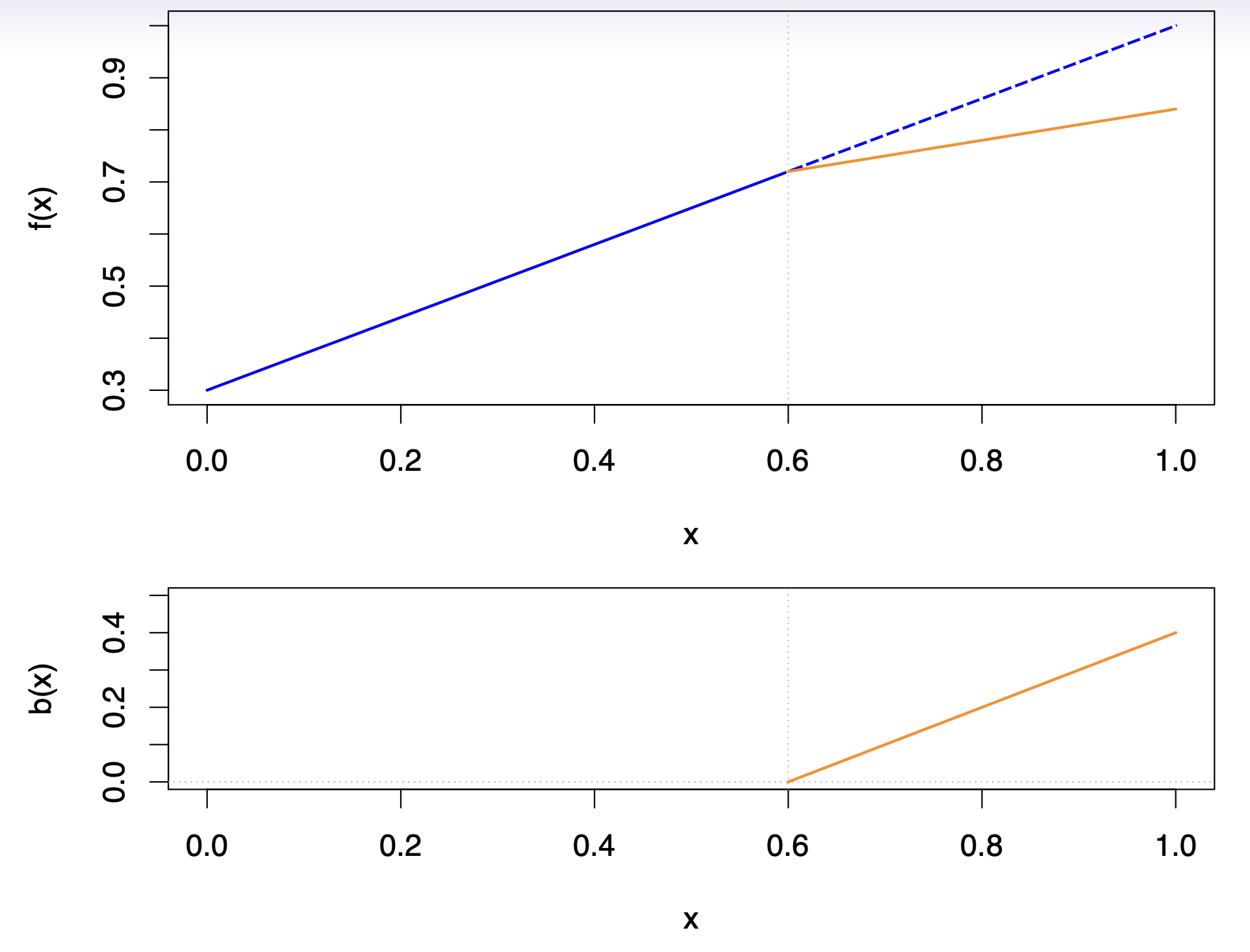
Top plot: shows two linear fits over the domain \(0 \le x \le 1\). The blue line represents a single global linear function (extending as the dashed line beyond the knot at \(x = 0.6\)), whereas the orange line demonstrates how adding a spline basis function allows the slope to change precisely at \(x = 0.6\).
Bottom plot: displays the corresponding basis function \(b(x) = (x - 0.6)_{+}\), which is defined to be zero for \(x \le 0.6\) and increases linearly for \(x > 0.6\). Because \(b(x)\) starts at zero at the knot, it does not introduce a jump—thus ensuring continuity—but it permits the slope to differ on either side of \(x = 0.6\).
- By including this basis function (and a coefficient for it) in a linear model, one can capture a “bend” or change in slope at the specified knot. More generally, introducing additional such functions at different knots yields a piecewise linear model that remains continuous but adapts its slope in each region.
Cubic Splines Visualization
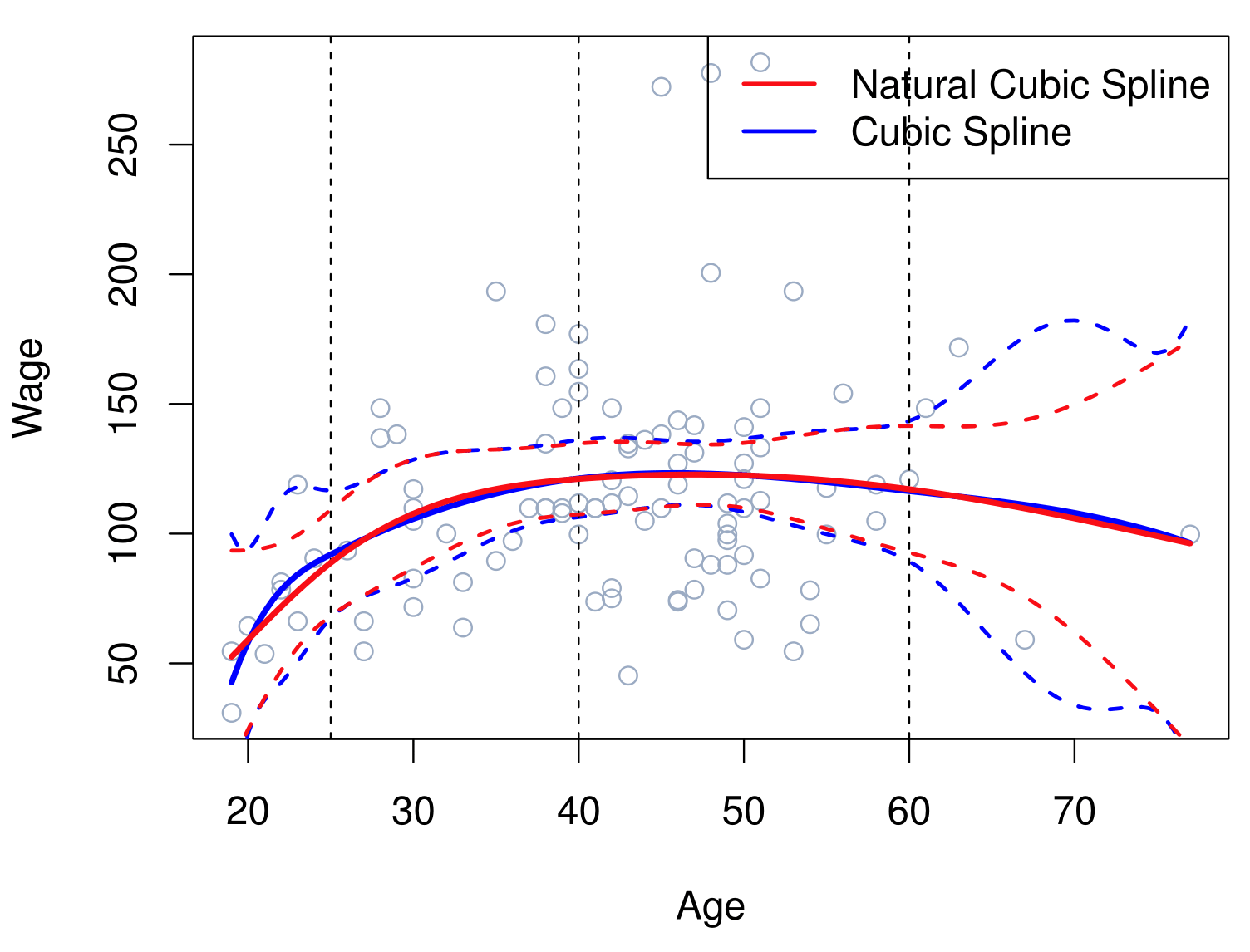
Natural Cubic Splines
A natural cubic spline extrapolates linearly beyond the boundary knots. This adds \(4 = 2 \times 2\) extra constraints, and allows us to put more internal knots for the same degrees of freedom as a regular cubic spline.
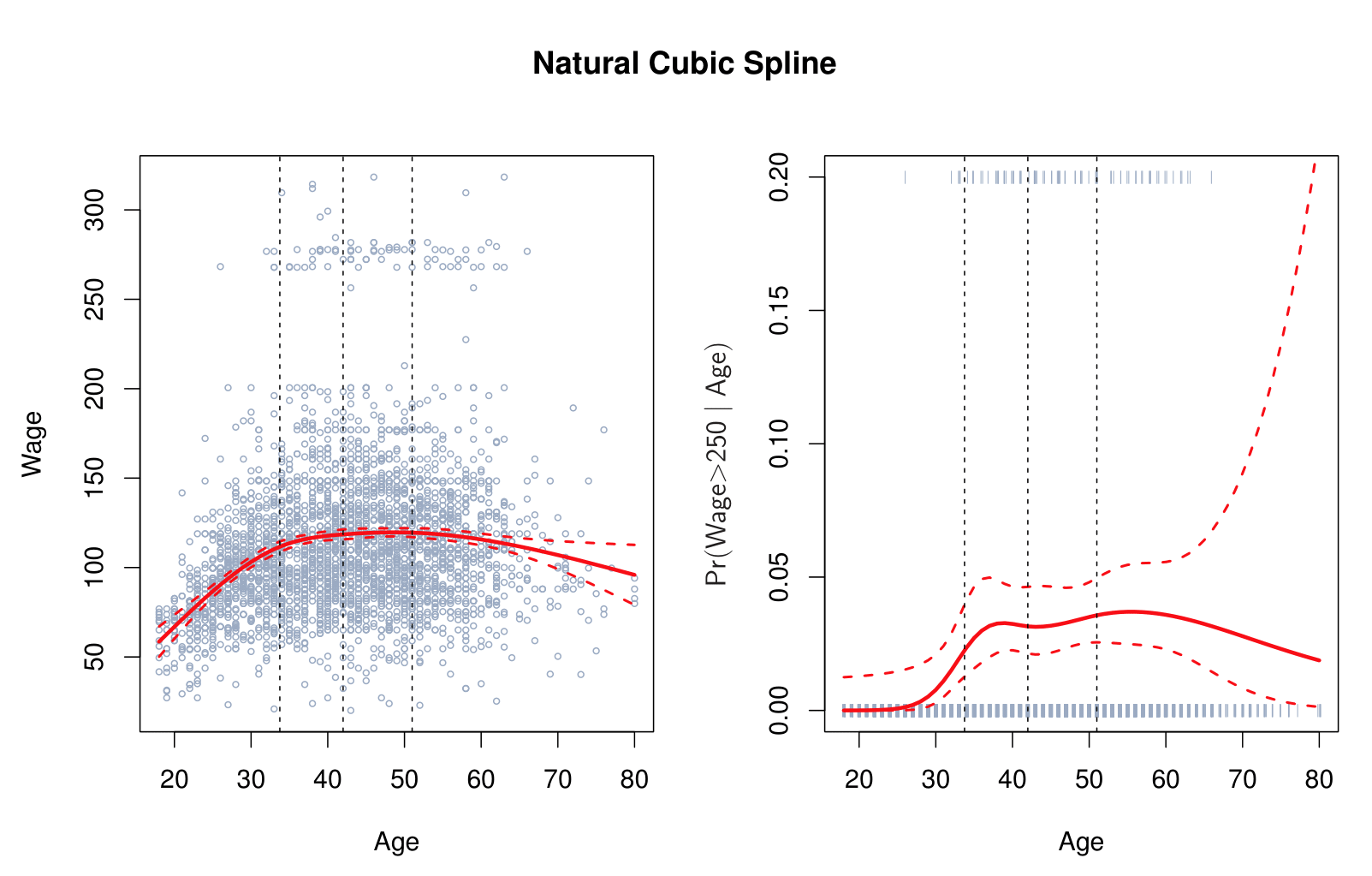
Natural Cubic Spline
Knot Placement
One strategy is to decide \(K\), the number of knots, and then place them at appropriate quantiles of the observed \(X\).
A cubic spline with \(K\) knots has \(K + 4\) parameters or degrees of freedom.
A natural spline with \(K\) knots has \(K\) degrees of freedom.
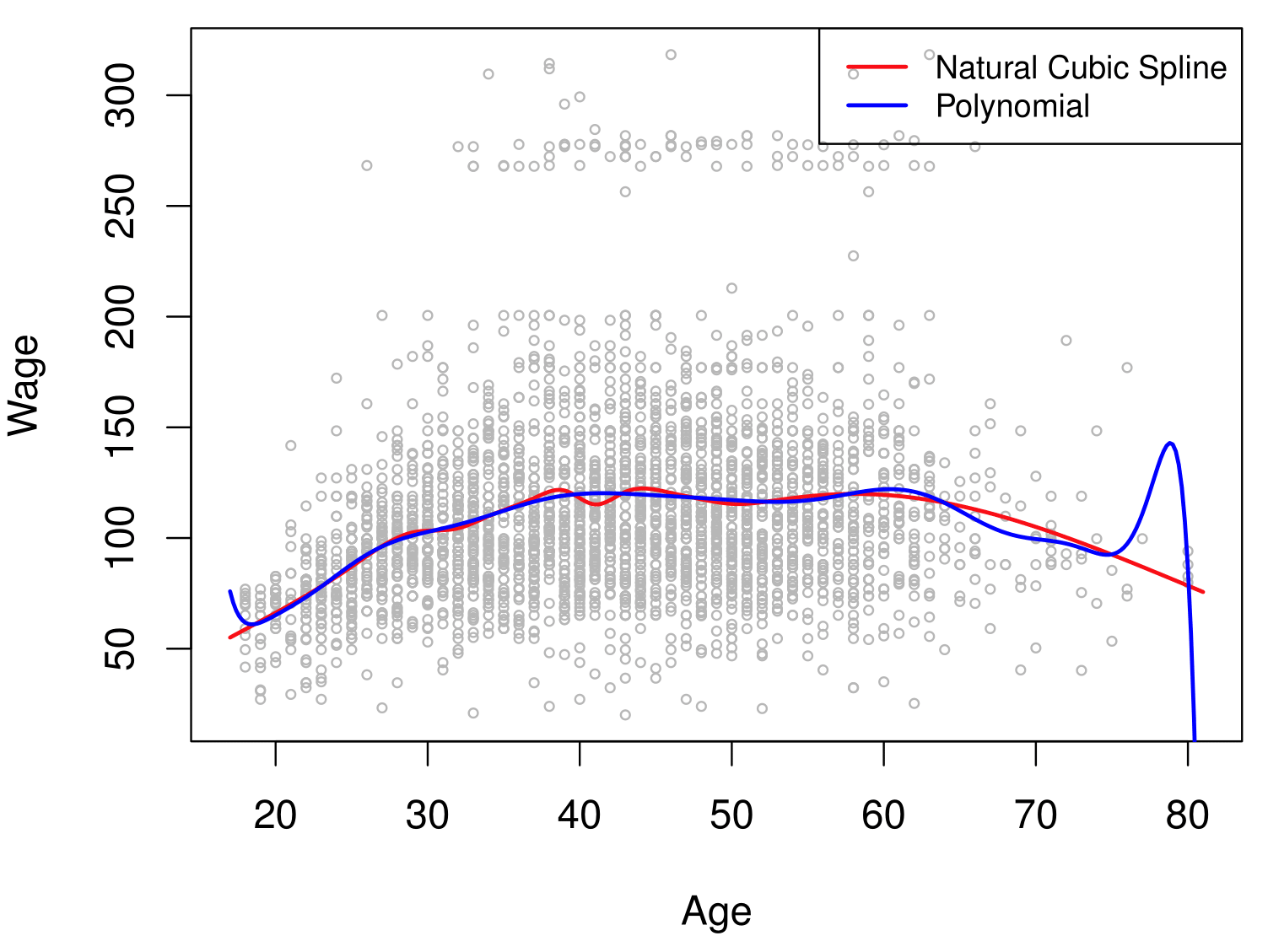
- Figure: Comparison of a degree-14 polynomial and a natural cubic spline, each with 15df.
Smoothing Spline: Degrees of Freedom

Local Regression
Local regression is similar to splines, but differs in an important way. The regions are allowed to overlap, and indeed they do so in a very smooth way.
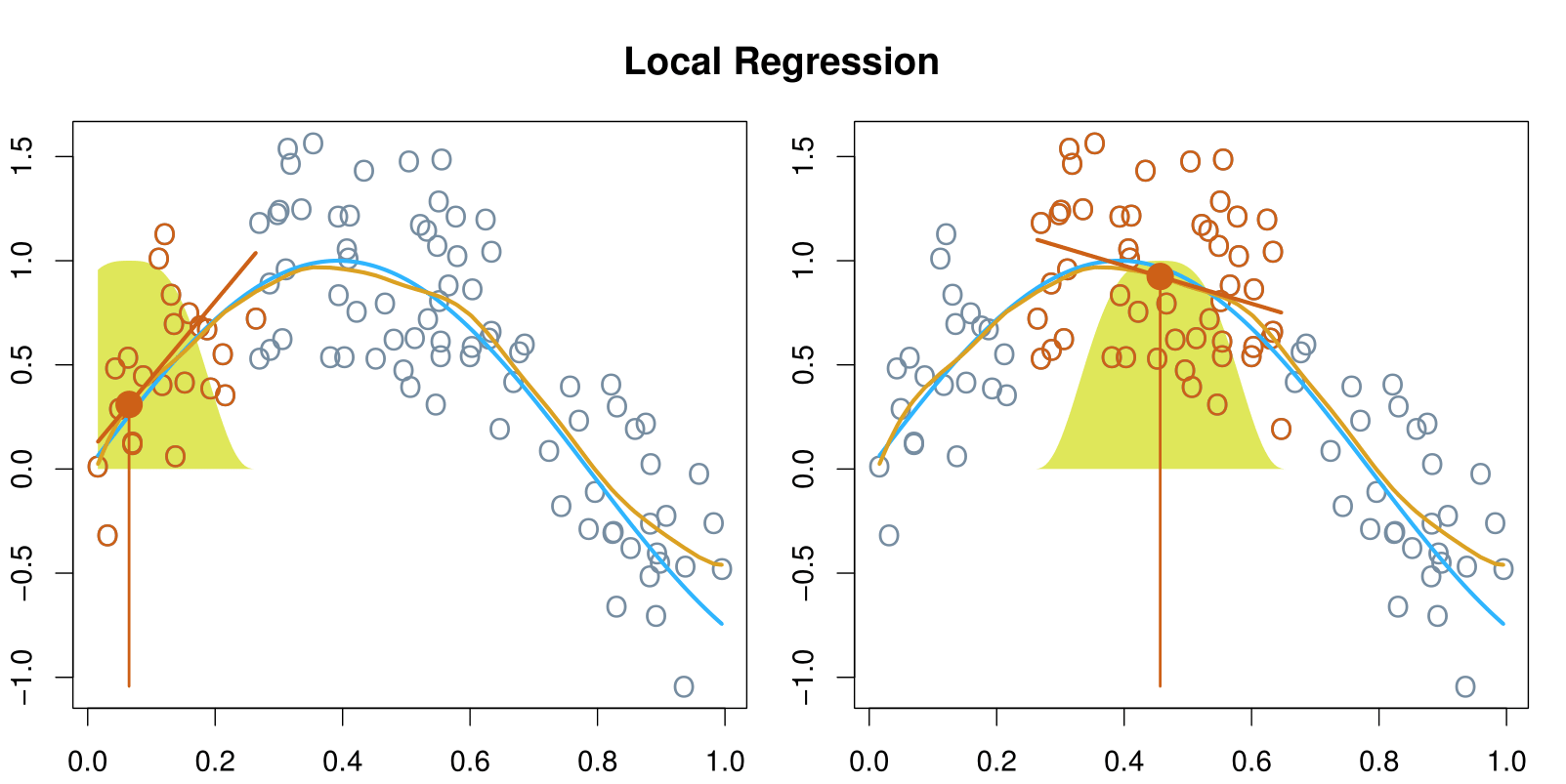
With a sliding weight function, we fit separate linear fits over the range of \(X\) by weighted least squares.
Generalized Additive Models
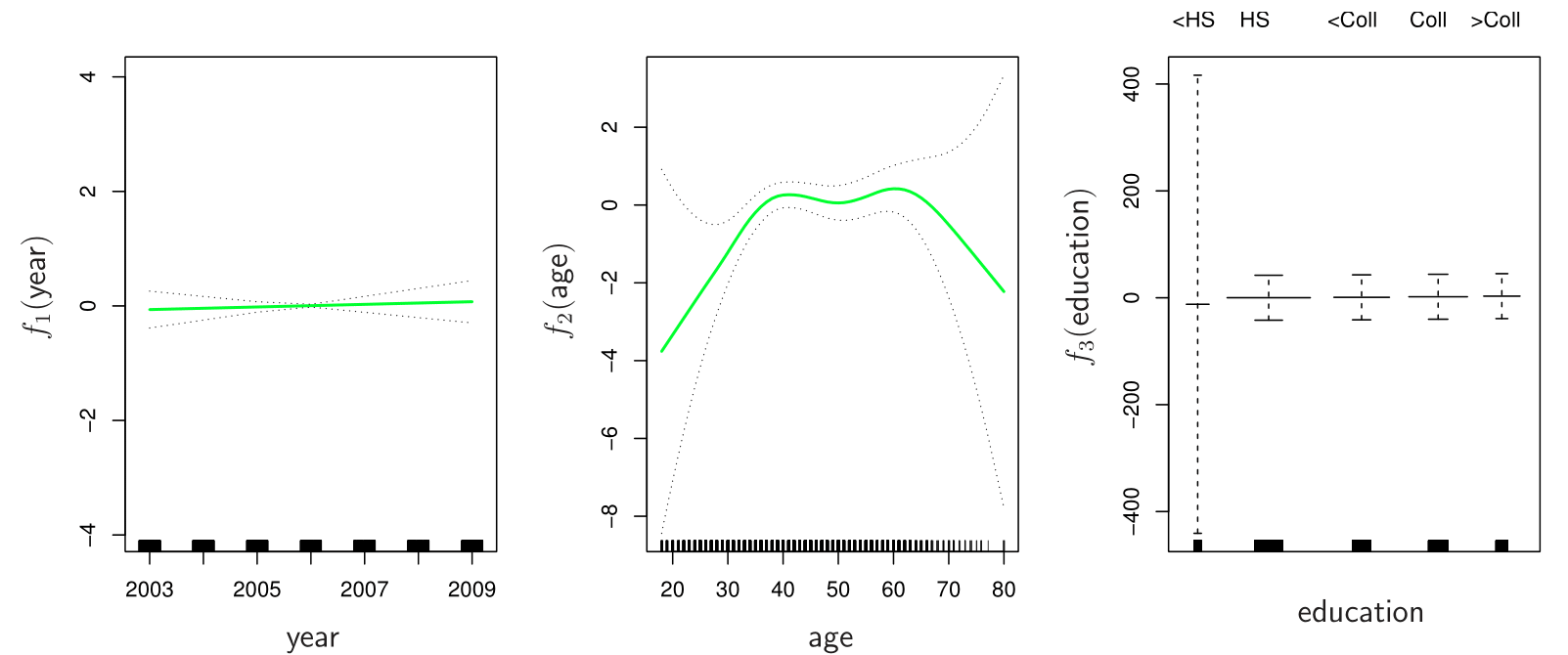
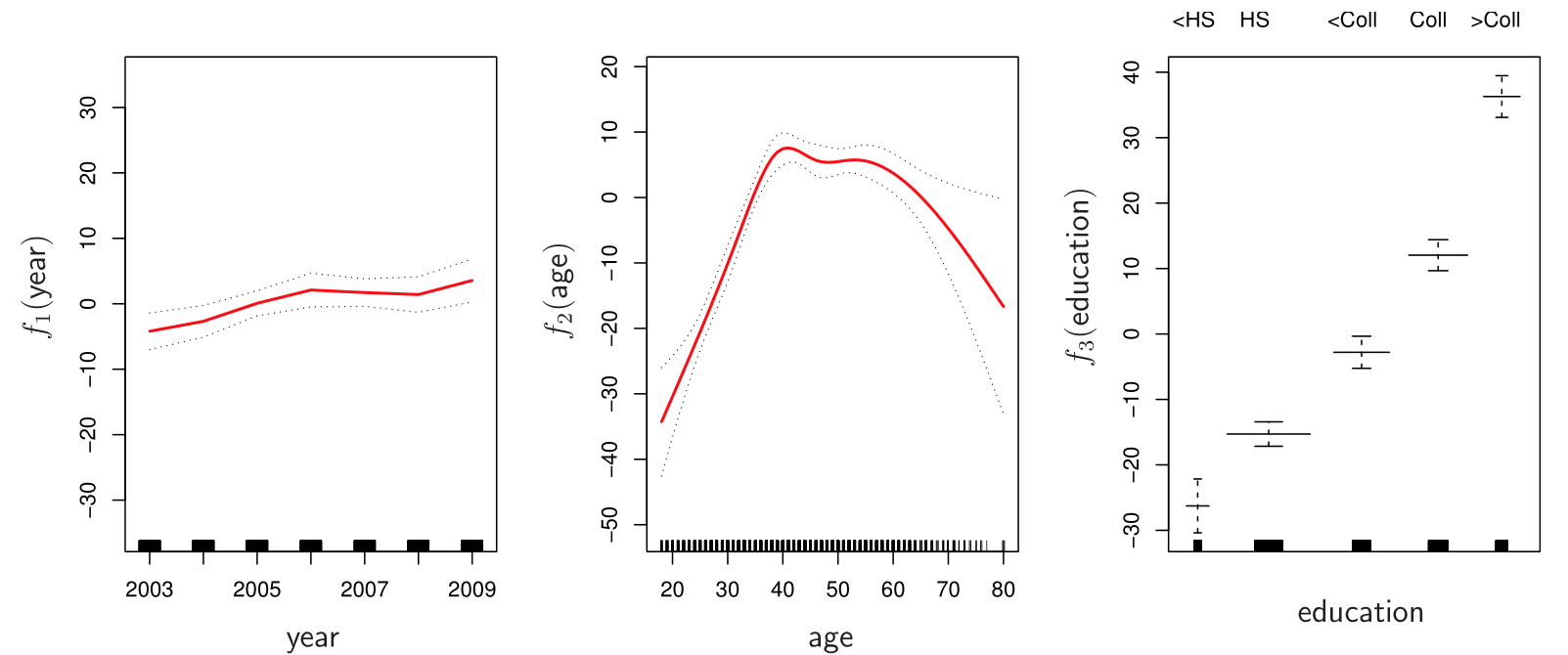
Generalized additive models (GAMs) allow us to extend the methods covered in this lecture to deal with multiple predictors.
GAMs allows for flexible nonlinearities in several variables, but retains the additive structure of linear models.
\[ y_i = \beta_0 + f_1(x_{i1}) + f_2(x_{i2}) + \cdots + f_p(x_{ip}) + \epsilon_i. \]
GAMs for Classification
\[ \log\left(\frac{p(X)}{1 - p(X)}\right) = \beta_0 + f_1(X_1) + f_2(X_2) + \cdots + f_p(X_p). \]