MGMT 47400: Predictive Analytics
Resampling Methods
Precision and Accuracy
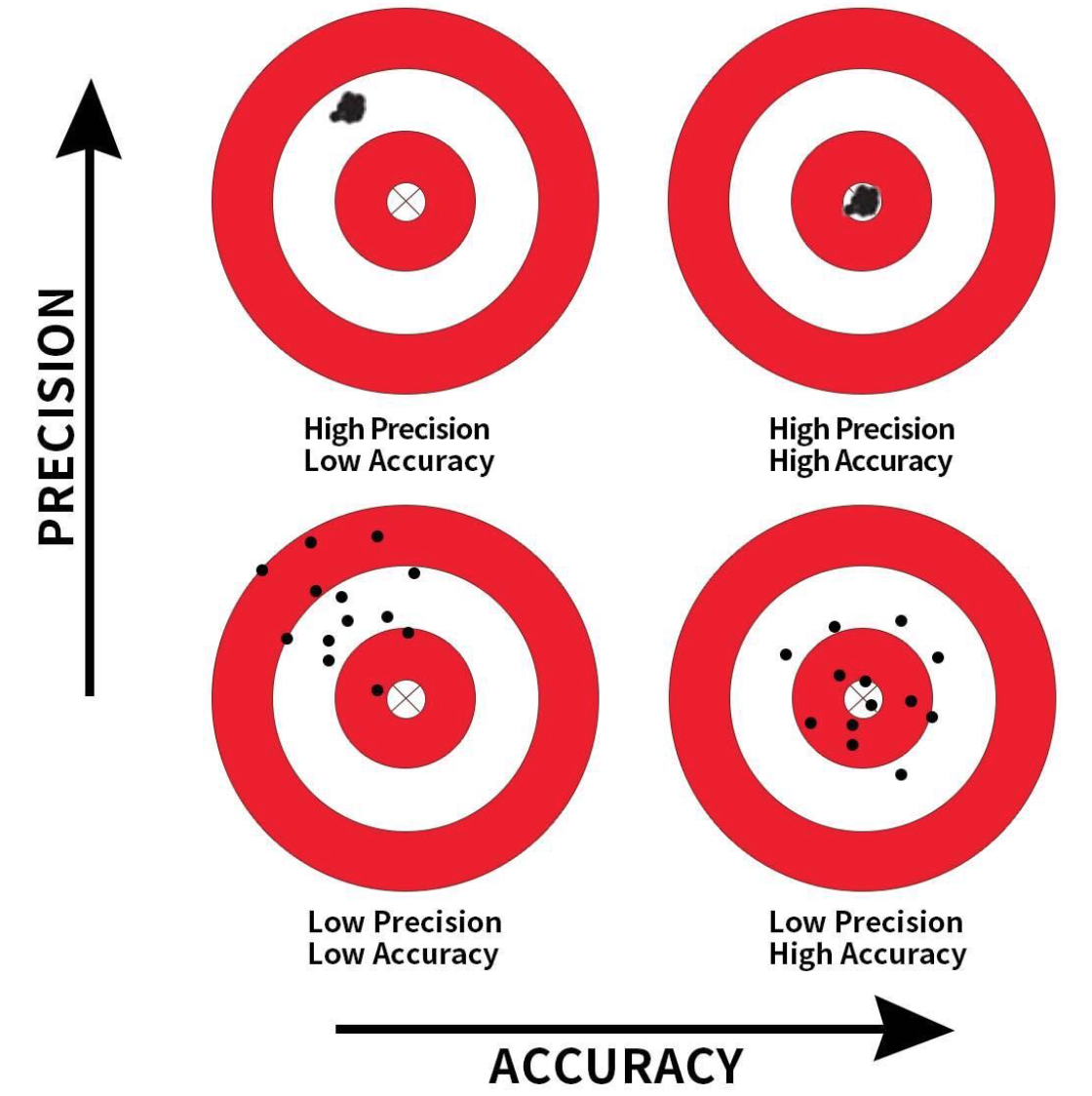
Precision: Refers to the consistency or reliability of the model’s predictions.
Accuracy: Refers to how close the model’s predictions are to the true values.
In the context of regression:
- High Precision, Low Accuracy: Predictions are consistent but biased.
- High Precision, High Accuracy: Predictions are both consistent and valid.
- Low Precision, Low Accuracy: Predictions are neither consistent nor valid.
- Low Precision, High Accuracy: Predictions are valid on average but have high variability.
The Validation Process
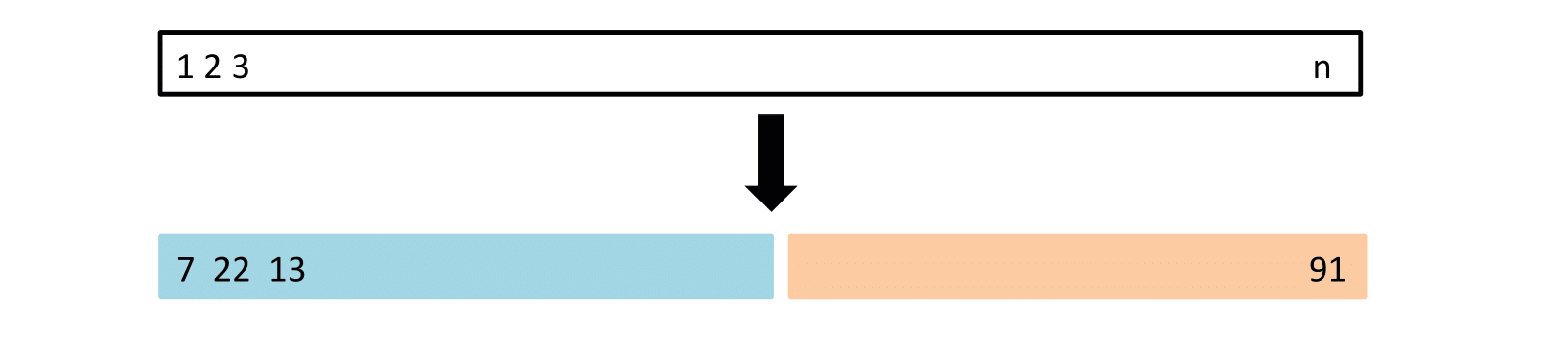
A random splitting of the original dataset into two halves (two-fold validation):
- Left part is the training set
- Right part is the validation set
Example: Automobile Data
Want to compare linear vs higher-order polynomial terms in a linear regression.
We randomly split the 392 observations into two sets:
- A training set containing 196 of the data points.
- A validation set containing the remaining 196 observations.
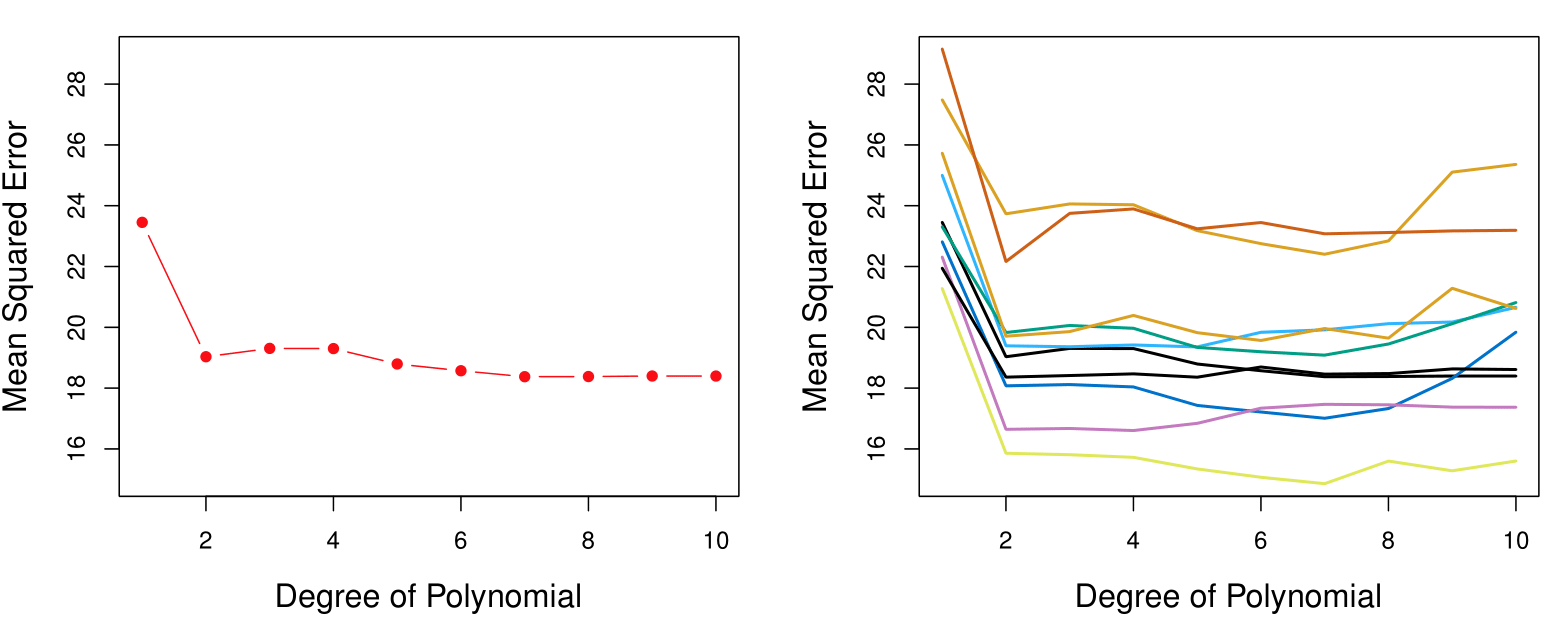
Left panel shows single split; right panel shows multiple splits.
K-Fold Cross-Validation in Detail
Divide data into \(K\) roughly equal-sized parts (\(K = 5\) here).
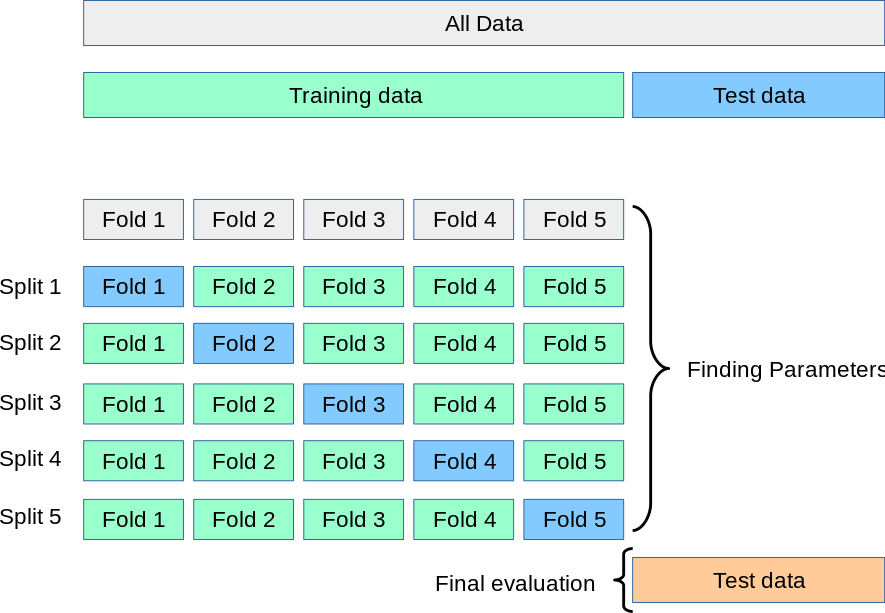
K-Fold Cross-Validation in Detail
Divide data into \(K\) roughly equal-sized parts (\(K = 3\) here).
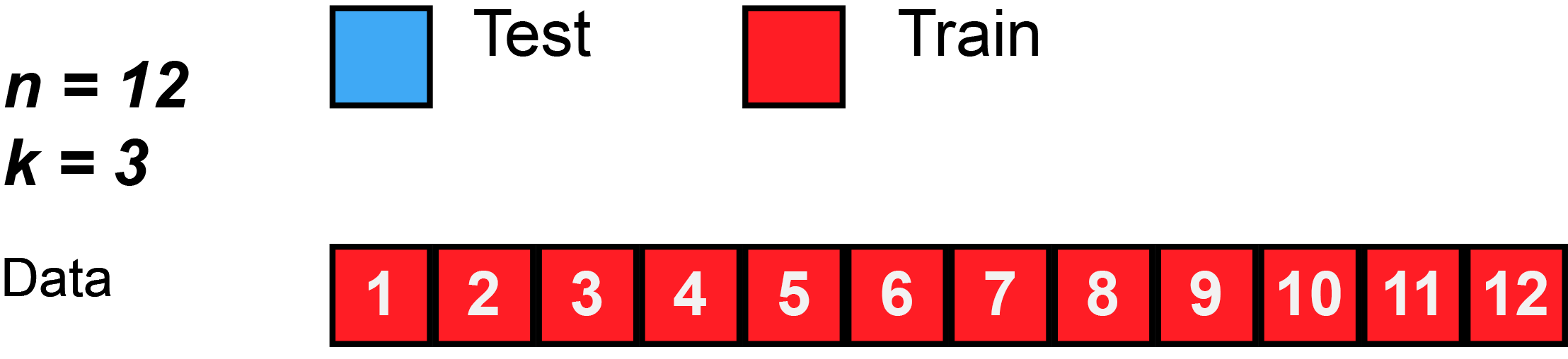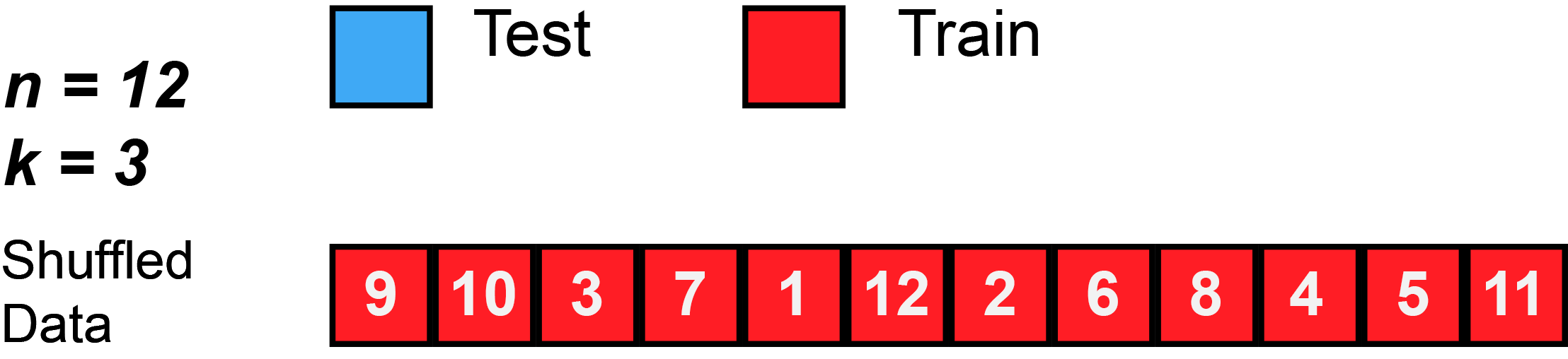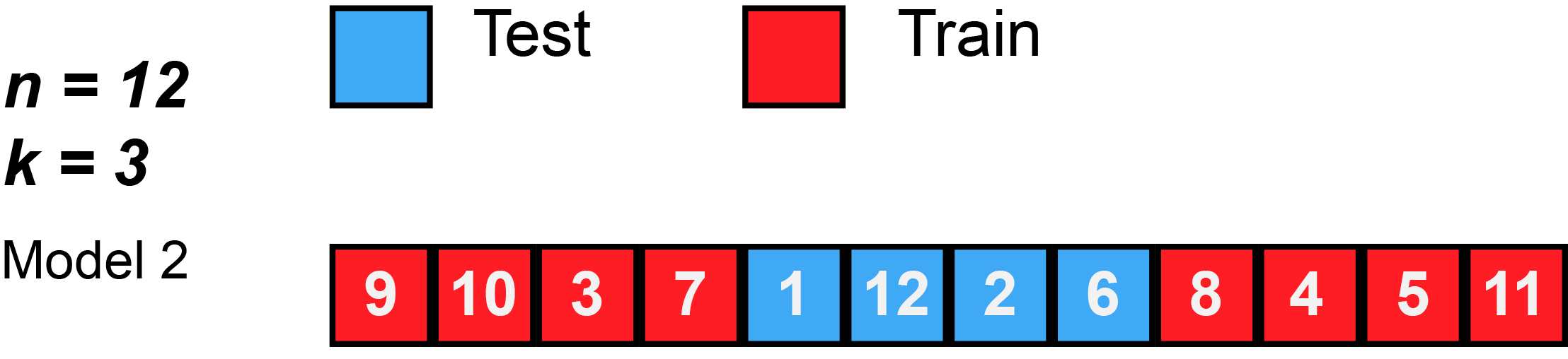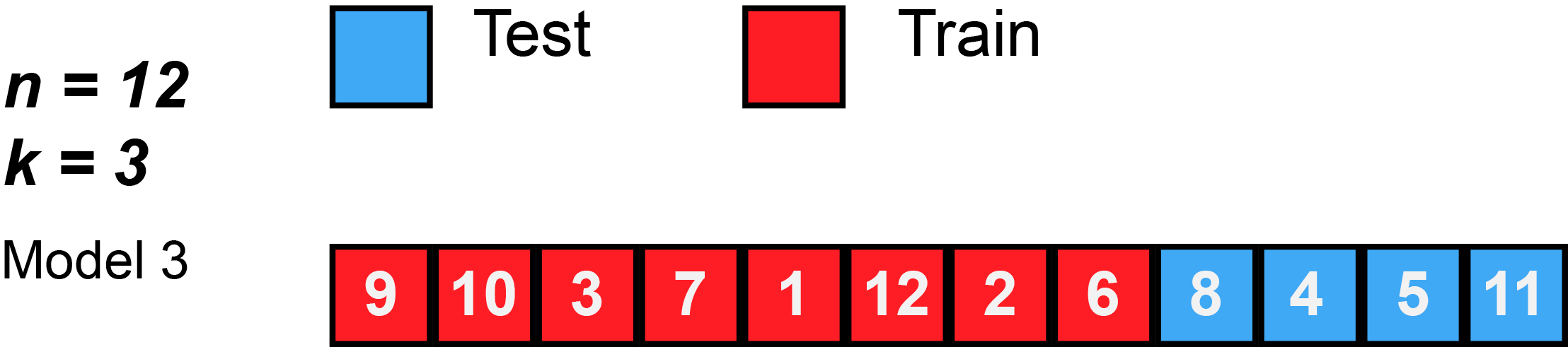
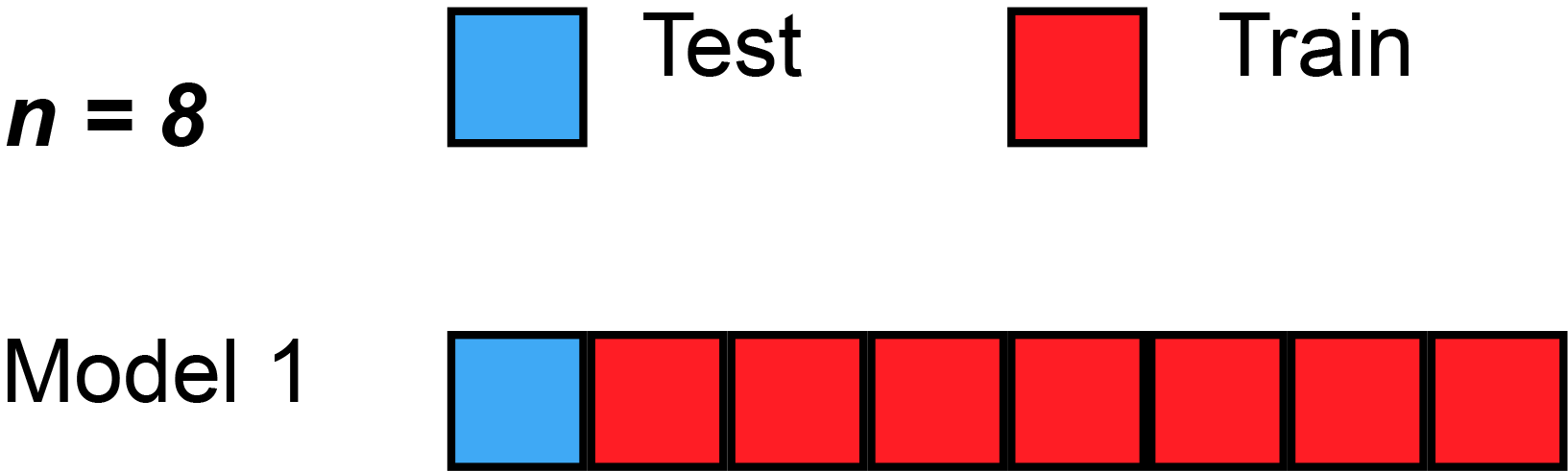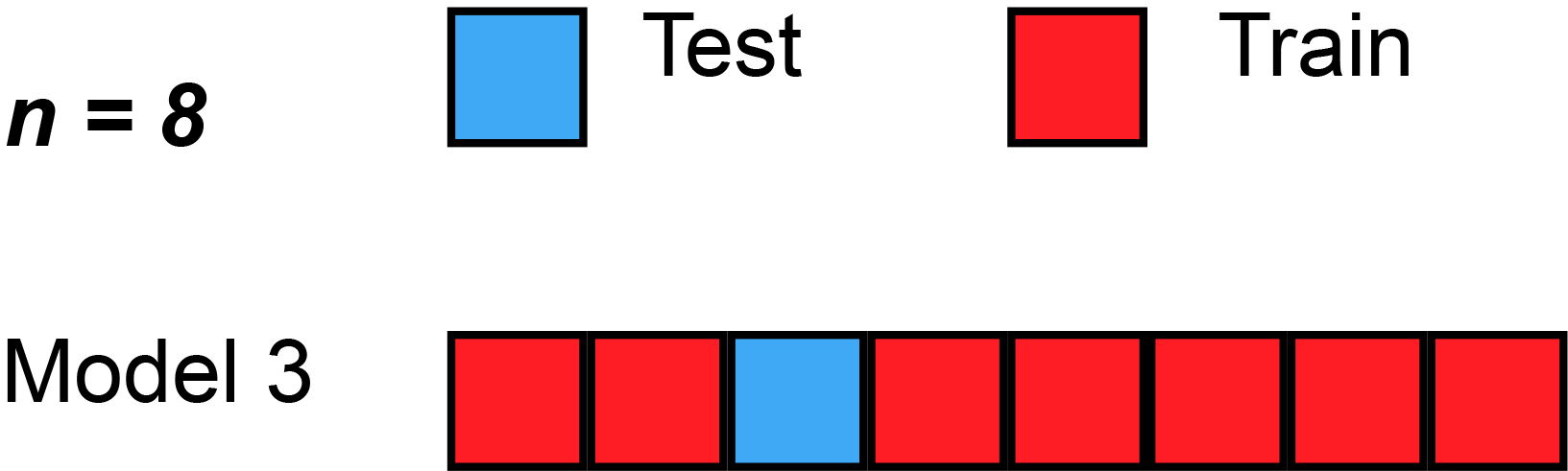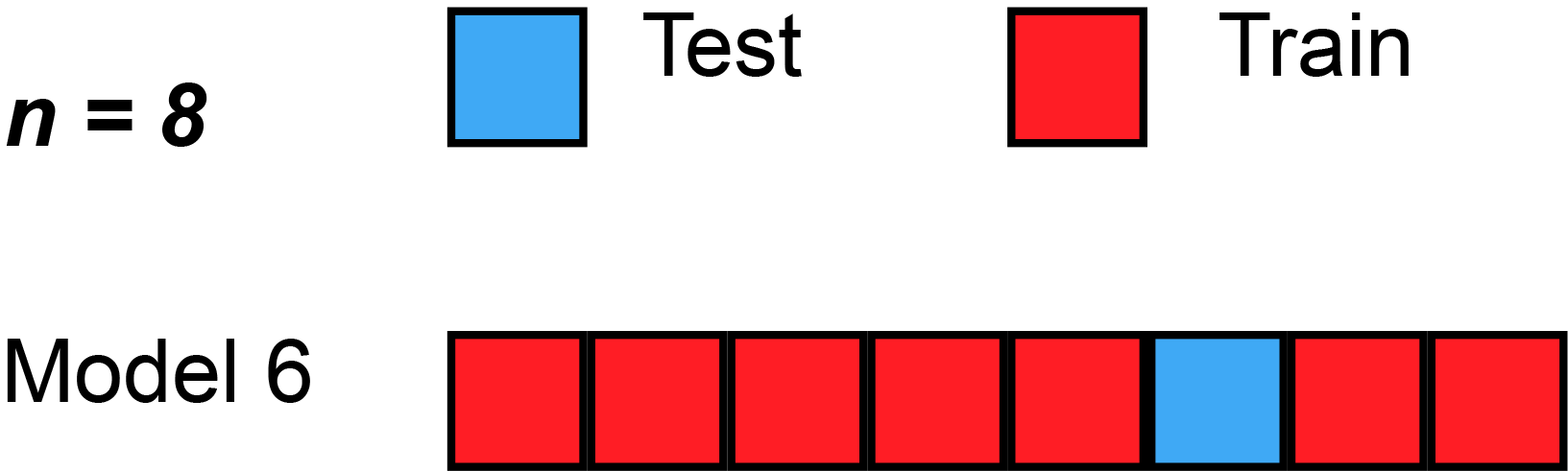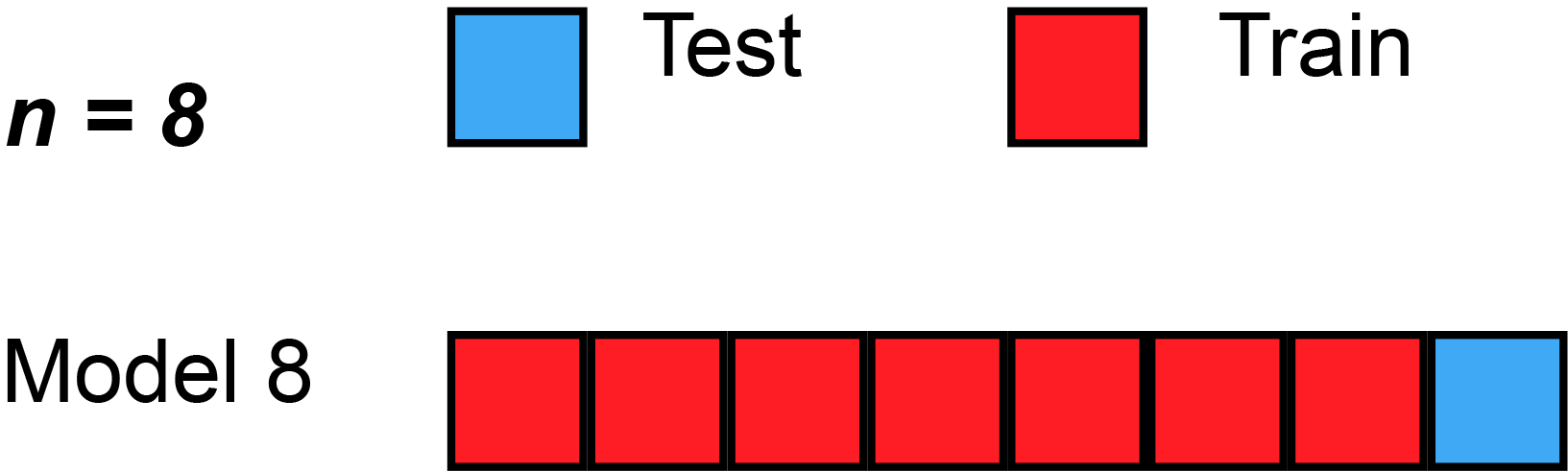
Leave-One-Out Cross-Validation (LOOCV)
Example: Auto Data Revisited
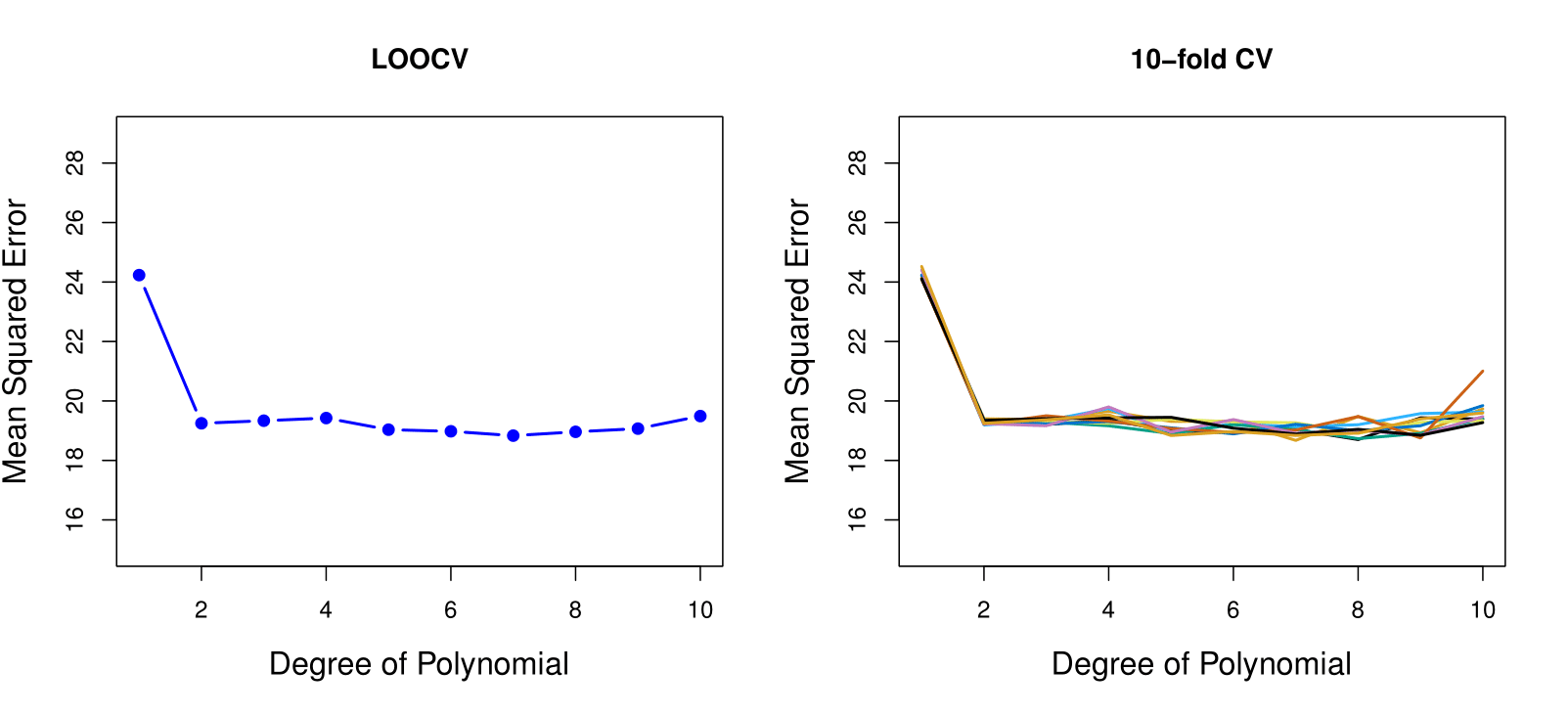
- Left plot: Similar to the two halve validation;
- Right plot: Tenfold cross validation. With 10 different partitions of the data to train and test the model we see there is not much variability. The results are consistent, in contrast to the result when we divided into two parts.
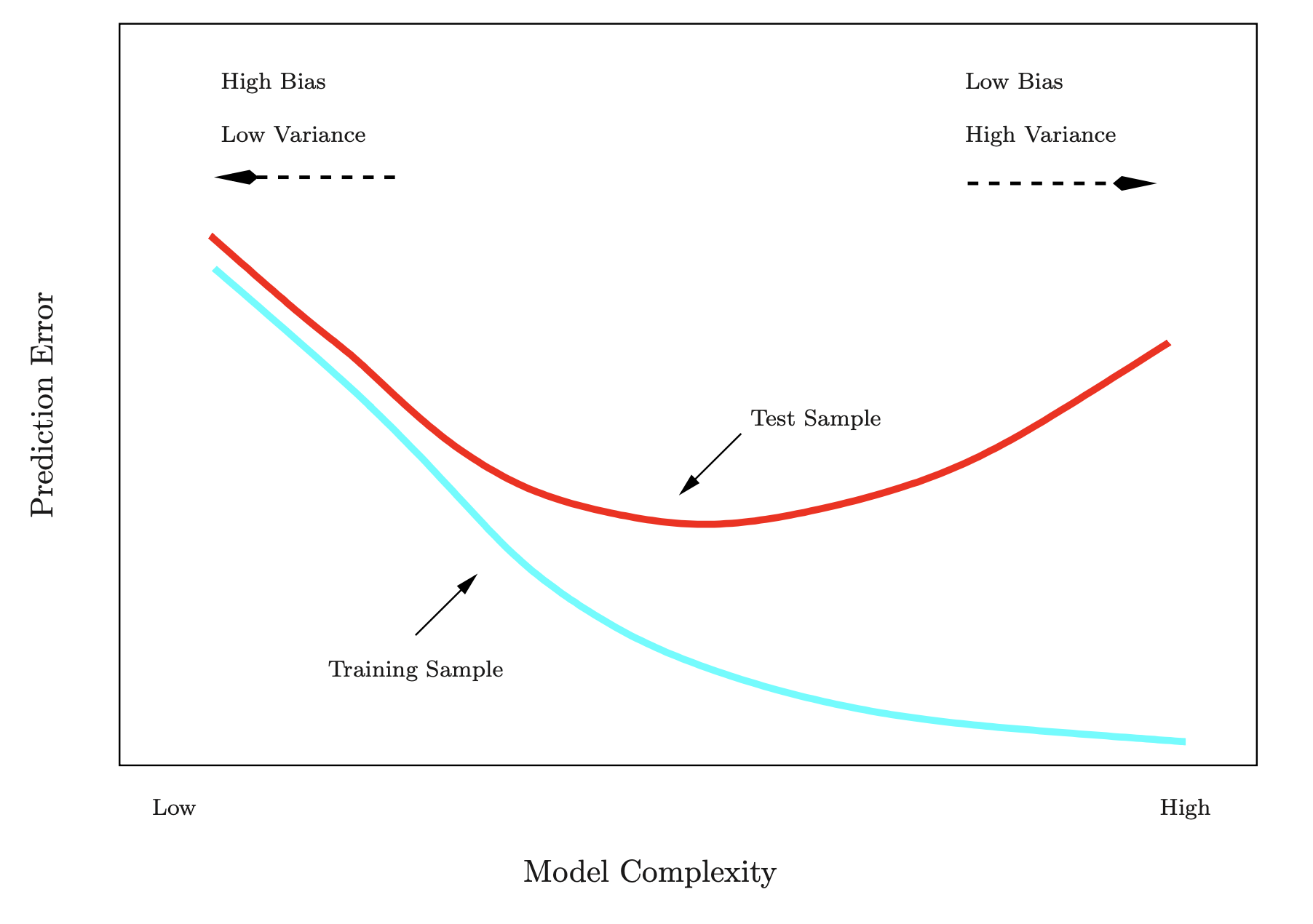
True and Estimated Test MSE for the Simulated Data
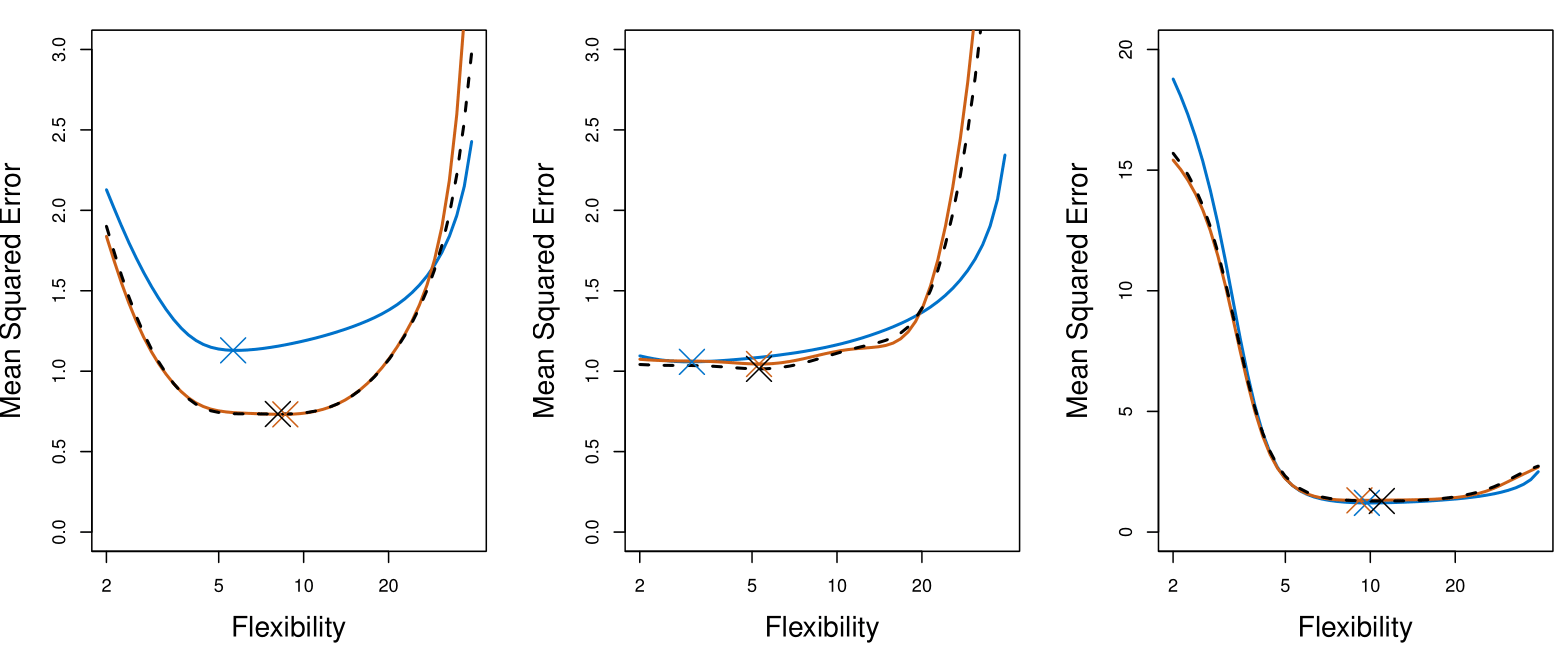
The plot presents the cross-validation estimates and true test error rates that result from applying smoothing splines to the simulated data sets illustrated in Figures 2.9–2.11 of Chapter 2 of the book.
The true test MSE is displayed in blue.
The black dashed and orange solid lines respectively show the estimated LOOCV and 10-fold CV estimates.
In all three plots, the two cross-validation estimates are very similar.
Right-hand panel: the true test MSE and the cross-validation curves are almost identical.
Center panel: the two sets of curves are similar at the lower degrees of flexibility, while the CV curves overestimate the test set MSE for higher degrees of flexibility.
Left-hand panel: the CV curves have the correct general shape, but they underestimate the true test MSE.
Example Continued
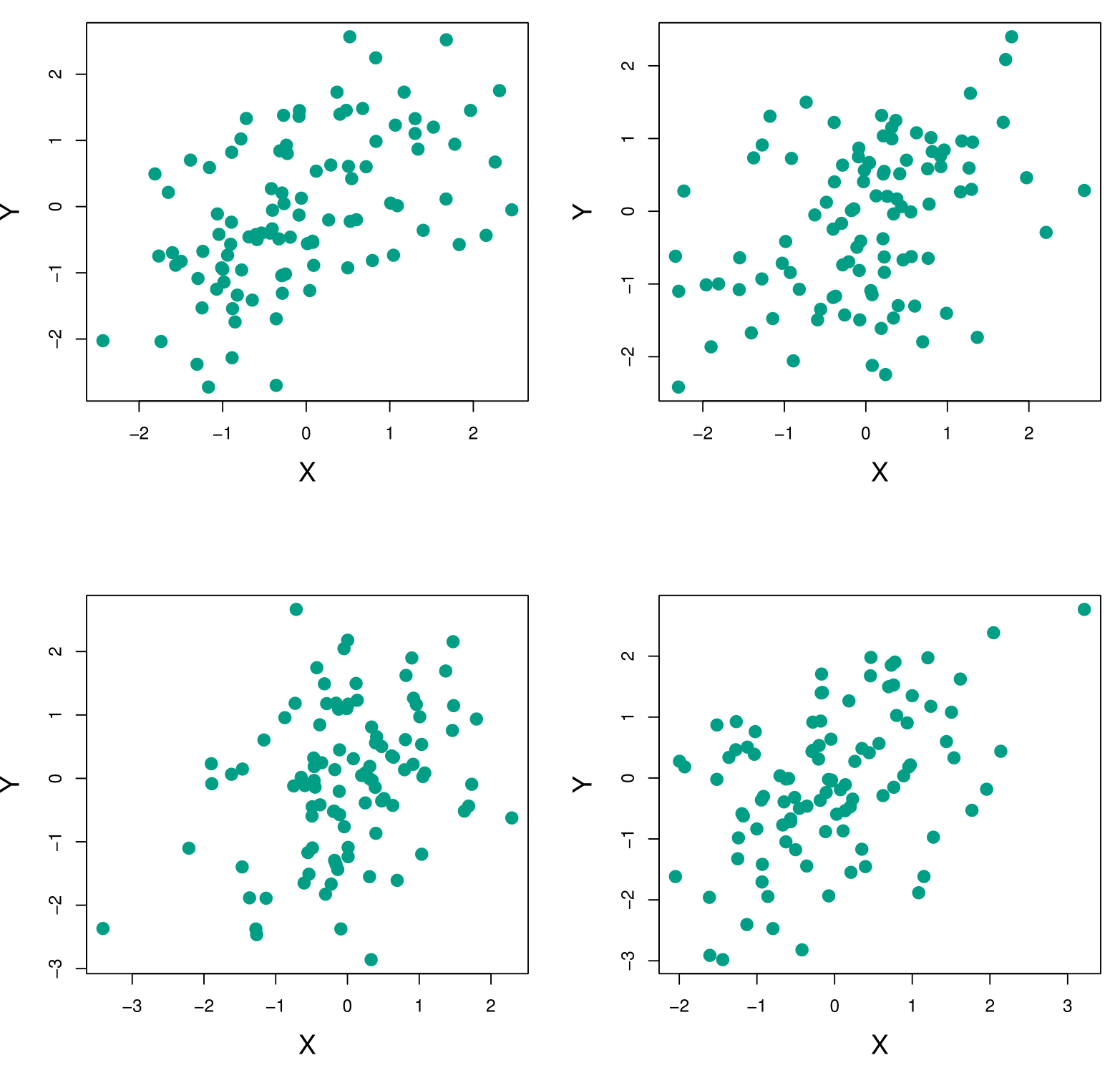
Each panel displays 100 simulated returns for investments X and Y. From left to right and top to bottom, the resulting estimates for \(\alpha\), the fraction to minimize the total risk, are 0.576, 0.532, 0.657, and 0.651.
Example Continued
To estimate the standard deviation of \(\hat{\alpha}\), we repeated the process of simulating 100 paired observations of \(X\) and \(Y\), and estimating \(\alpha\) 1,000 times.
We thereby obtained 1,000 estimates for \(\alpha\), which we can call \(\hat{\alpha}_1, \hat{\alpha}_2, \ldots, \hat{\alpha}_{1000}\).
The left-hand panel of the Figure displays a histogram of the resulting estimates.
For these simulations, the parameters were set to \(\sigma_X^2 = 1, \, \sigma_Y^2 = 1.25, \, \sigma_{XY} = 0.5,\) and so we know that the true value of \(\alpha\) is 0.6 (indicated by the red line).
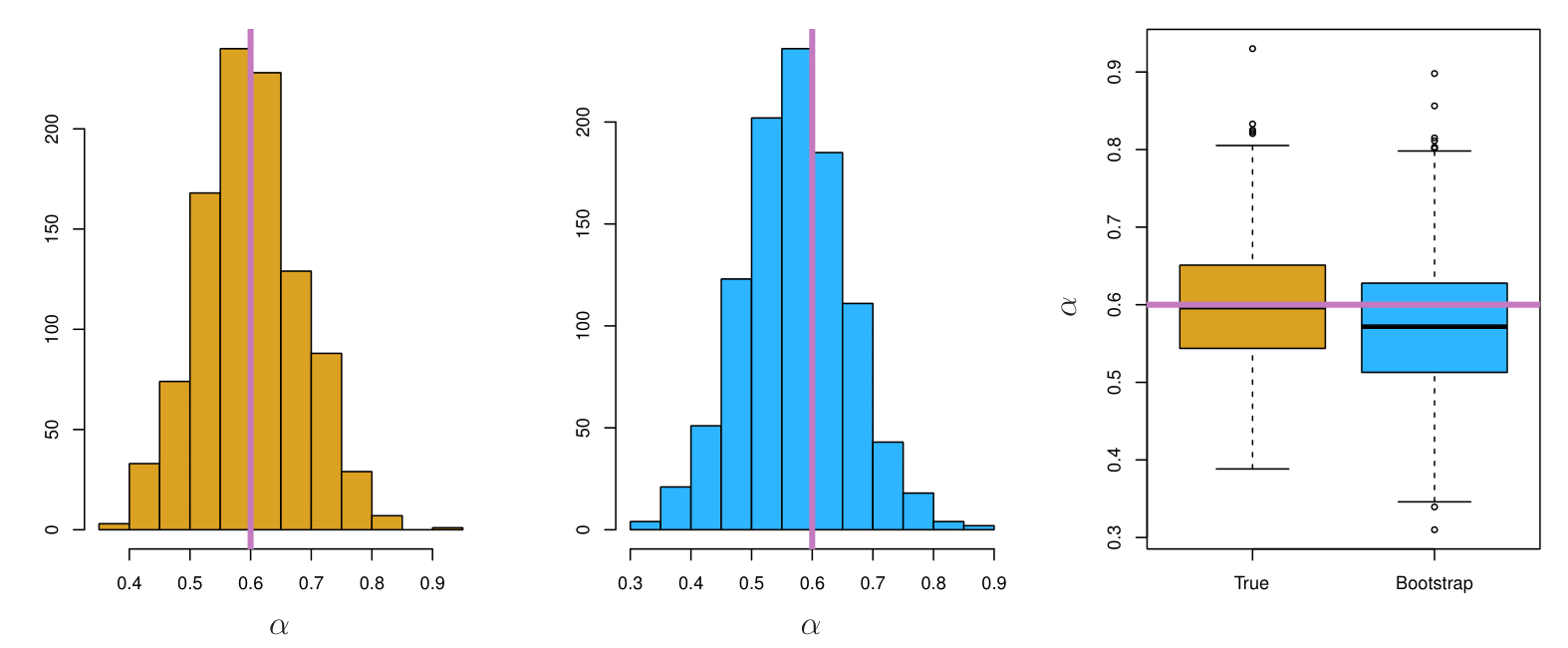
Example Results
Left: A histogram of the estimates of \(\alpha\) obtained by generating 1,000 simulated data sets from the true population.
Center: A histogram of the estimates of \(\alpha\) obtained from 1,000 bootstrap samples from a single data set.
Right: The estimates of \(\alpha\) displayed in the left and center panels are shown as boxplots.
- In each panel, the pink line indicates the true value of \(\alpha\).
Example with Just 3 Observations
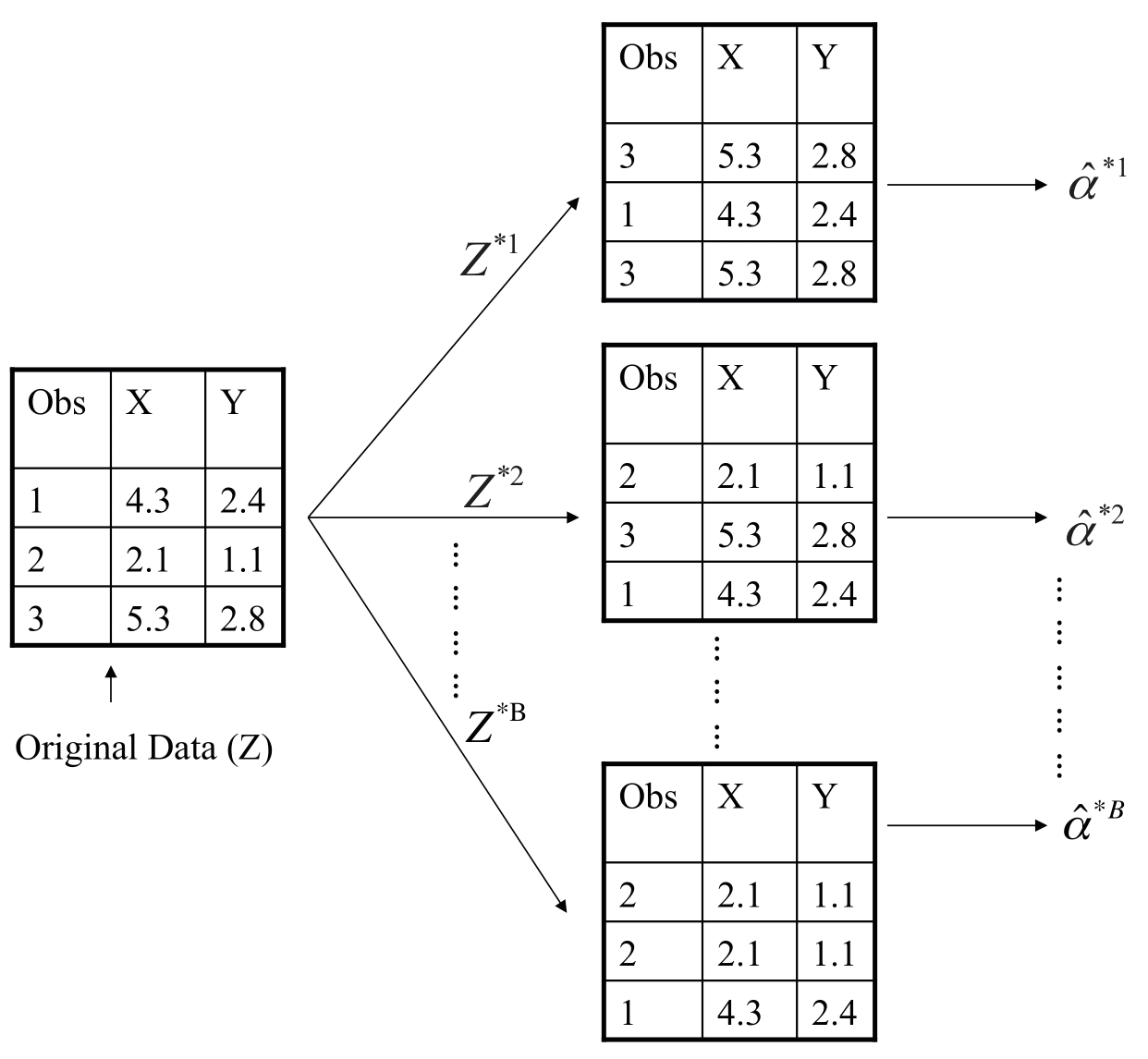
- A graphical illustration of the bootstrap approach on a small sample containing \(n = 3\) observations.
- Each bootstrap data set contains \(n\) observations, sampled with replacement from the original data set.
- Each bootstrap data set is used to obtain an estimate of \(\alpha\).
A General Picture for the Bootstrap
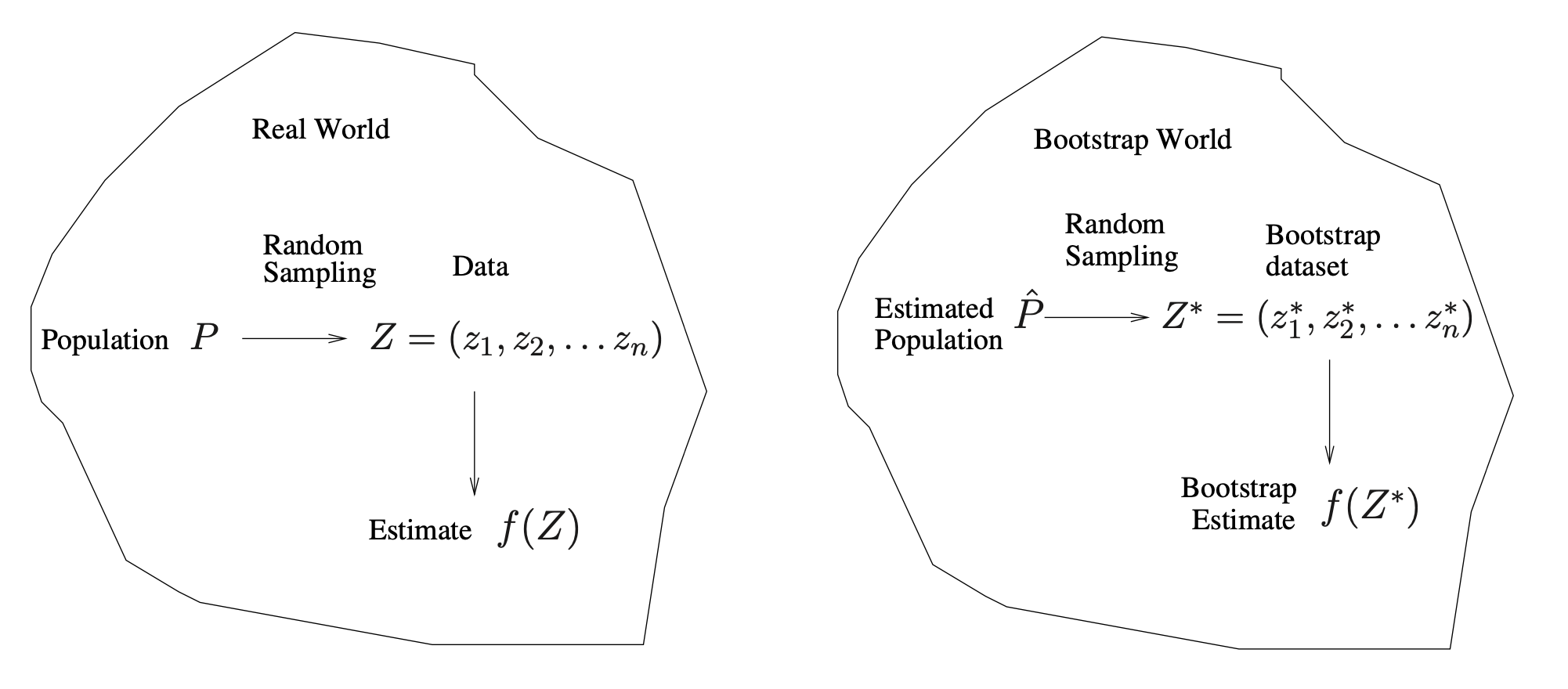
Real World
- Population \(P\)
- We imagine there is a true, unknown population (or data‐generating process).
- In practice, we typically do not have direct access to all of \(P\).
- We imagine there is a true, unknown population (or data‐generating process).
- Random Sampling
- We draw a finite sample \(Z = (z_1, z_2, \dots, z_n)\) from the population \(P\).
- This sample \(Z\) is our observed dataset (often called the “training data” in applied work).
- We draw a finite sample \(Z = (z_1, z_2, \dots, z_n)\) from the population \(P\).
- Estimate \(f(Z)\)
- From this observed data \(Z\), we compute a statistic or estimate, denoted \(f(Z)\).
- Examples might include a mean, a regression coefficient, or (in the investment example) an optimal allocation parameter \(\alpha\).
- From this observed data \(Z\), we compute a statistic or estimate, denoted \(f(Z)\).
In short, the Real World side shows how our single dataset \(Z\) arrives by randomly sampling from the true population \(P\).
Bootstrap World
- Estimated Population \(\hat{P}\)
- Because we usually cannot sample repeatedly from the real population \(P\), the bootstrap creates a stand‐in population \(\hat{P}\). We ‘replace’ the population by our sample.
- \(\hat{P}\) is the empirical distribution function of the observed data \(Z\). Informally, it assigns probability \(\tfrac{1}{n}\) to each observed point in \(Z\).
- Random Sampling from \(\hat{P}\)
- To mimic drawing new data from the real population, we instead draw (with replacement) from \(\hat{P}\).
- This produces a bootstrap dataset \(Z^* = (z_1^*, z_2^*, \dots, z_n^*)\). Each \(z_i^*\) is sampled (with replacement) from among the original observed points \(\{z_1, \dots, z_n\}\).
- To mimic drawing new data from the real population, we instead draw (with replacement) from \(\hat{P}\).
- Bootstrap Estimate \(f(Z^*)\)
- We compute the same statistic (or estimator) on each bootstrap sample, giving \(f(Z^*)\).
- By repeating this bootstrap sampling many times, we obtain a distribution of estimates \(\{f(Z^*_1), f(Z^*_2), \dots\}\). This approximates how \(f(Z)\) would vary if we could repeatedly resample from the true population.
- We compute the same statistic (or estimator) on each bootstrap sample, giving \(f(Z^*)\).