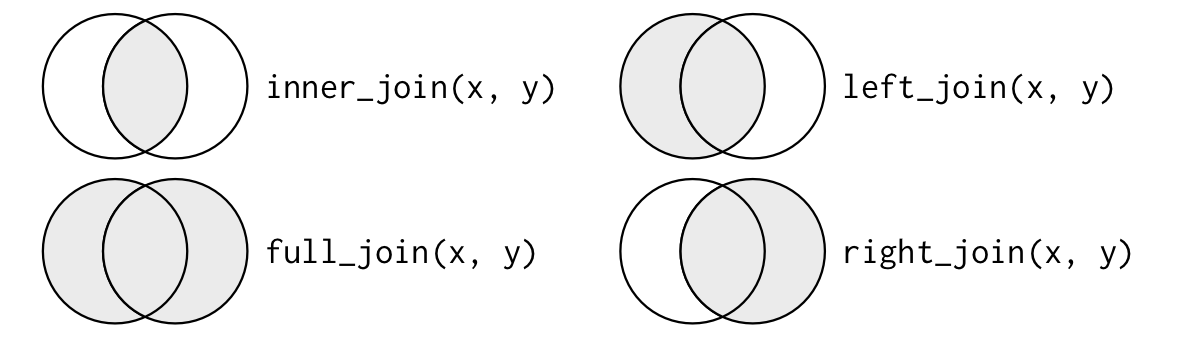“Happy families are all alike; every unhappy family is unhappy in its own way.”
— Leo Tolstoy
“Tidy datasets are all alike; every messy dataset is messy in its own way.”
— Hadley Wickham
Tidy Data
Tidy Data vs. Messy Data
In the real world, most data will not be in the format we desire. In this class, we will learn how to process data so that it becomes tidy according to our objectives.
Tidy Dataset
Tidyverse
Tidyverse
All the tools we will see are part of the tidyverse, a set of packages for data manipulation.
The %>% or |> makes the order of operations clearer, making code easier to read and understand.
# A random vectorx <-c(1:10)# A simple calculation with complicated codesum(sqrt(factorial(x)))# The same calculation with %>% x %>%factorial() %>%sqrt() %>%sum()
Data Wrangling
What is Data Wrangling?
Data Wrangling (Data Cleaning / Data Munging):
The process of transforming raw, messy data into a clean and structured format that is ready for analysis.
It often involves:
Handling missing values
Correcting inconsistencies
Reshaping data from wide to long formats (or vice versa)
Filtering, arranging, and summarizing data
Why is it Important?
Improved Data Quality:
Reliable analyses start with clean, accurate, and consistent data.
Efficiency in Analysis:
Data prepared in a structured and “tidy” format reduces the time spent fixing errors and allows focus on actual insights.
Better Decision Making:
High-quality, well-structured data leads to more meaningful interpretations, stronger conclusions, and actionable insights.
Loading Data
It is advisable to adopt a project-based workflow in your data analysis (Workflow: projects).
Using a consistent project structure optimizes collaboration and sharing of your analysis.
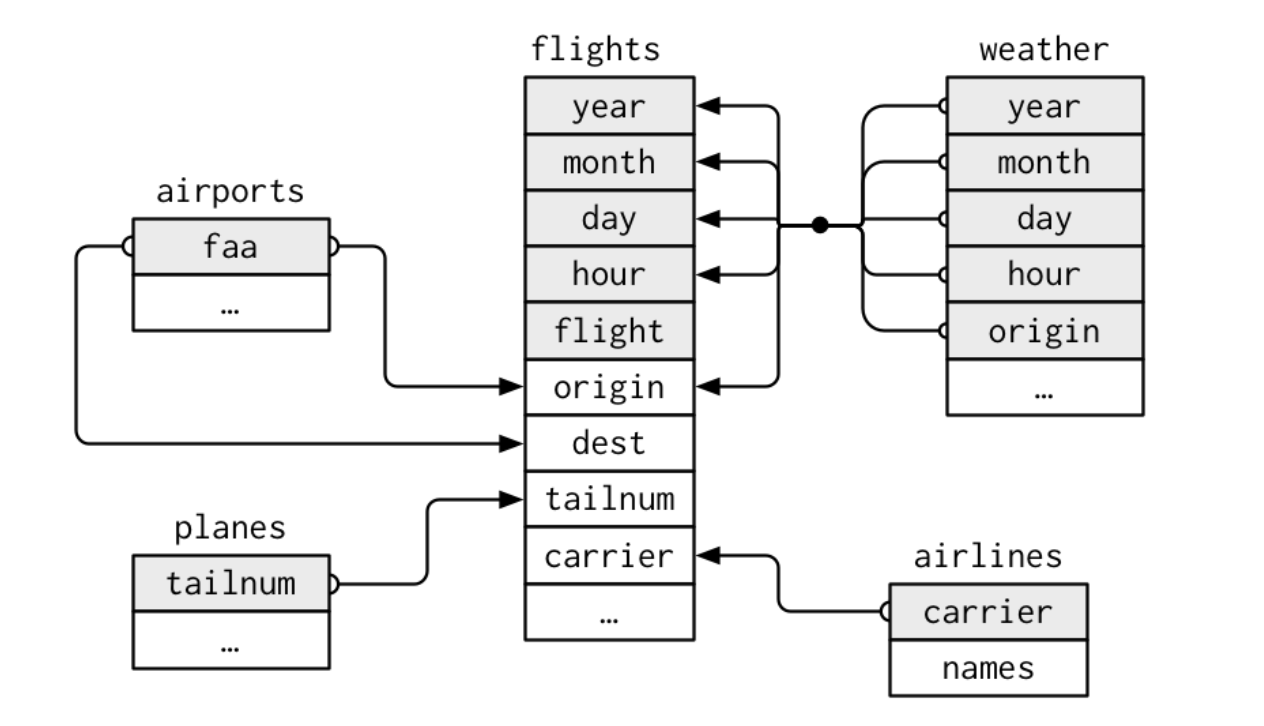
For this lecture, we will use the nycflights13 package, which comes with several related datasets about flights departing from NYC in 2013.
Loading Data
if(!require(nycflights13)) install.packages("nycflights13")library(nycflights13)# The main dataset we'll use is flightsflights <- nycflights13::flights
The flights dataset includes information on all US domestic flights departing NYC in 2013. Some key variables include:
year, month, day: date of departure
dep_delay, arr_delay: departure and arrival delays in minutes
carrier: airline carrier
origin and dest: origin and destination airports
Verbs in the Tidyverse
In the tidyverse, we use verbs (functions) that describe step-by-step data manipulation tasks:
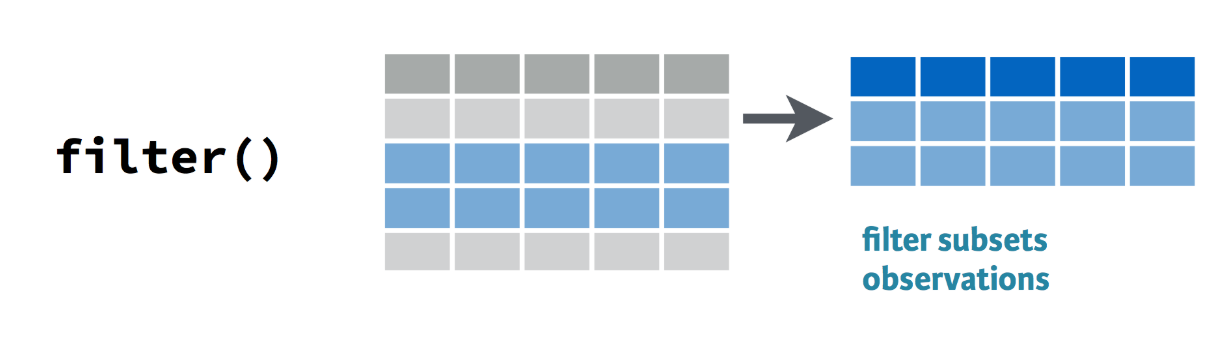
filter(): Select rows
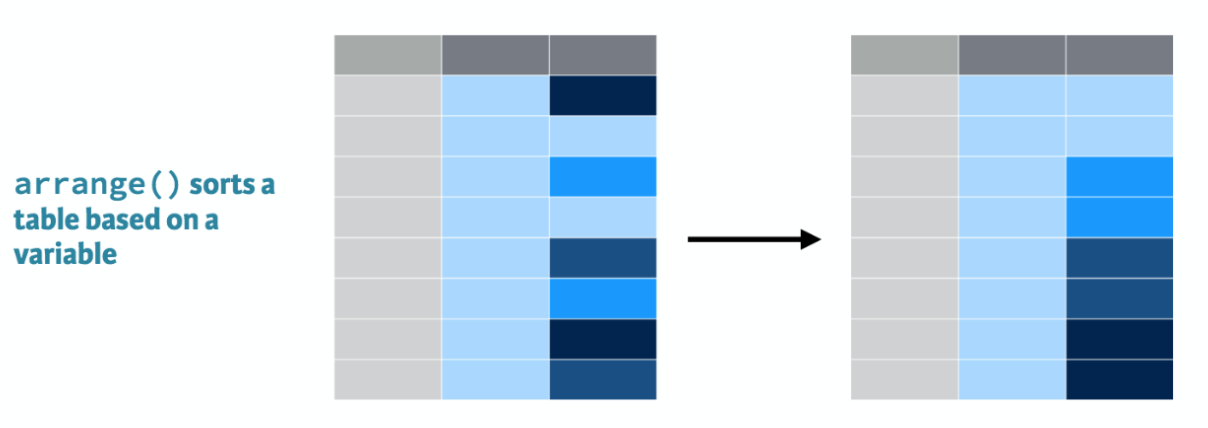
arrange(): Sort observations
select() and rename(): Select or rename columns
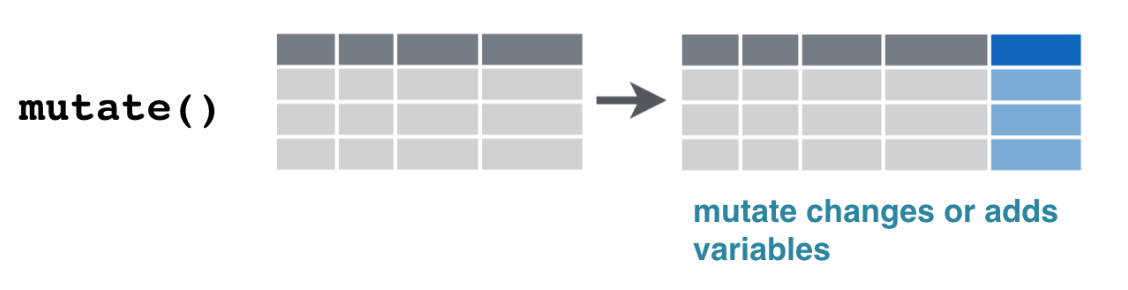
mutate(): Create new variables
case_when(): Recode variables
summarise() and group_by(): Summarize information
pivot_wider() and pivot_longer(): Reshape data
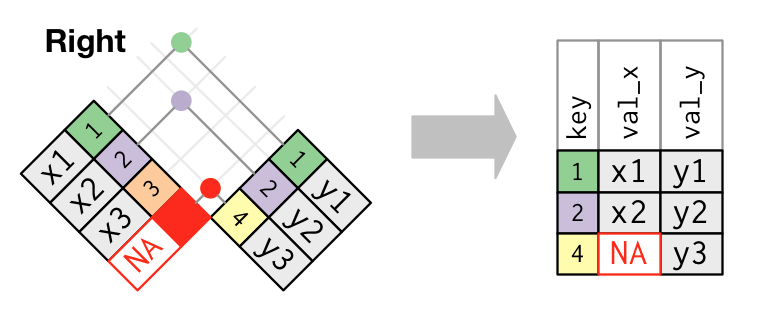
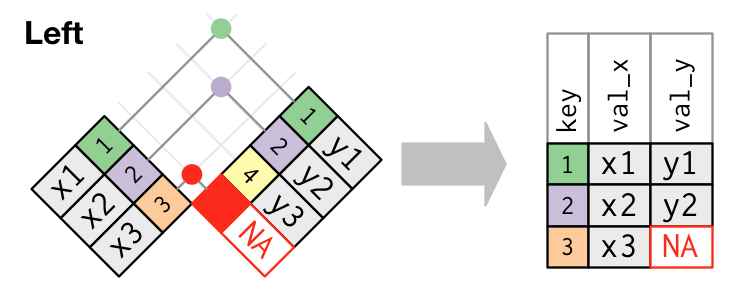
left_join(): Merge datasets
Combine different steps using the %>% or |>
Selecting Columns with select()
The flights dataset has many columns. We can choose only the ones we need:
# Select only a few important columnsflights %>%select(year, month, day, dep_delay, arr_delay)# Select all columns except a fewflights %>%select(-tailnum, -time_hour)
Selecting Columns with select()
# Select columns that start with 'arr'arr_data <- flights %>%select(starts_with("arr"))# Rearrange the order of variablesflights_reordered <- flights %>%select(carrier, flight, everything())
Renaming Variables with rename()
If we want to rename a variable:
# IMPORTANT: the new name is given firstflights %>%rename(airline = carrier) %>%select(airline, flight, dep_delay)
Creating Variables with mutate()
Creating Variables with mutate()
We can create new variables based on existing ones. For example, create a total delay variable:
Summarizing Information with summarise() and group_by()
summarise() computes summary statistics. Paired with group_by(), it creates summaries within groups. For example, find the average departure delay by airline carrier: