library(leaps)
# Fit the best subset model
best_model <- regsubsets(mpg ~ ., data = mtcars, nbest = 1)
# Extract the summary of the model
best_model_summary <- summary(best_model)
# Extract metrics
bic_values <- best_model_summary$bic
# Find the best model indices based on each criterion
best_bic_index <- which.min(bic_values)
# Display the best models based on the chosen criteria
cat("\nBest model based on BIC includes:\n")
print(coef(best_model, best_bic_index))MGMT 17300: Data Mining Lab
Evaluating Predictive Model Performance
August 01, 2024
Course Learning Milestones
Evaluating Predictive Model Performance
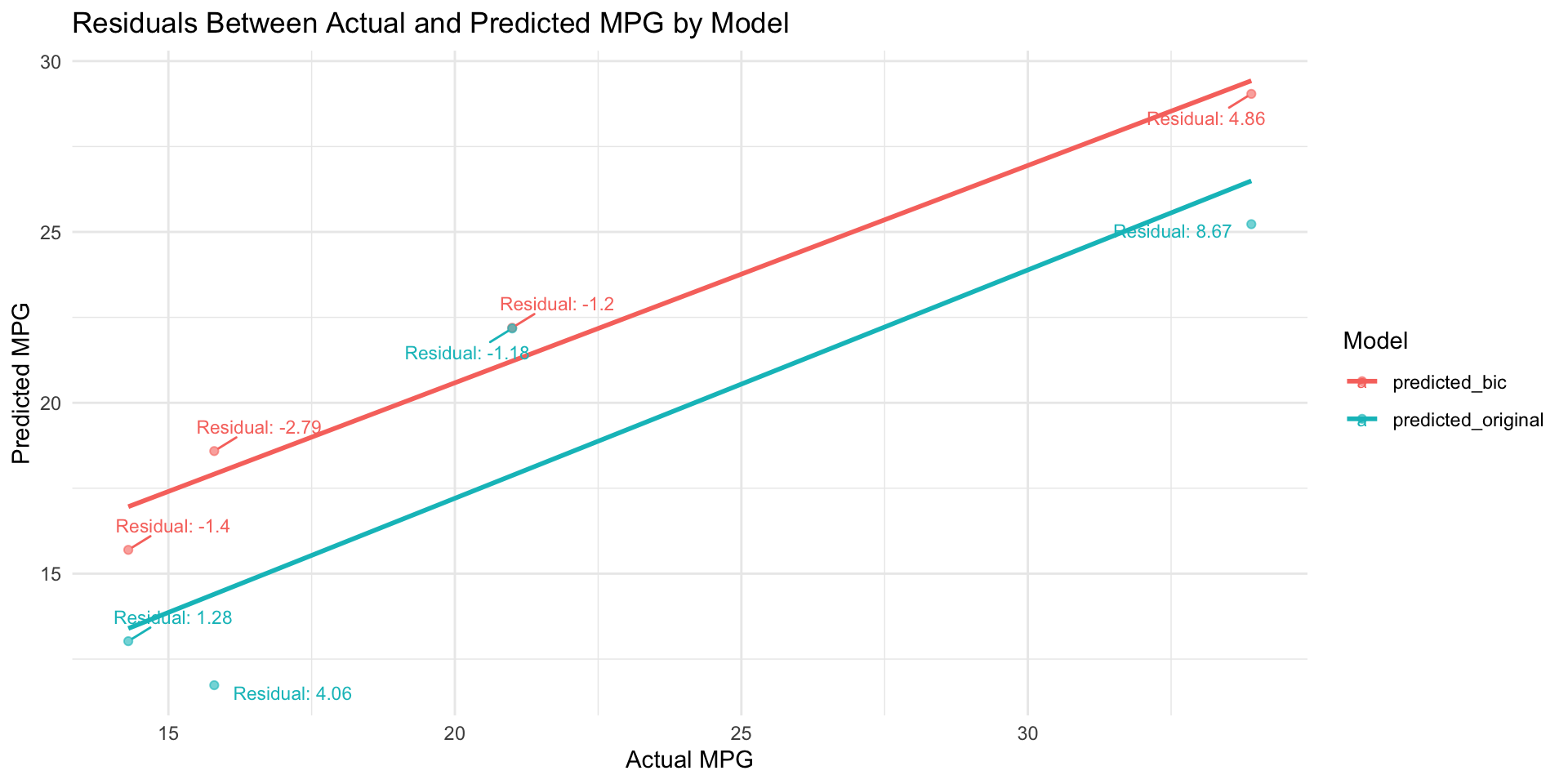
We can plot a scatter plot with the actual mpg values on the x-axis and predicted mpg values on the y-axis.
# Load ggrepel for better label placement
library(ggrepel)
# Create a scatter plot with residuals labeled and prediction lines
ggplot(plot_data, aes(x = actual, y = predicted, color = model)) +
geom_point(alpha = 0.6) + # Scatter plot of actual vs predicted
geom_smooth(method = "lm", formula = y ~ x, se = FALSE) + # Linear trend lines
geom_text_repel(
aes(label = paste0("Residual: ", round(actual - predicted, 2))), # Residual as label
size = 3,
max.overlaps = 10, # Controls the maximum number of overlapping labels
box.padding = 0.5, # Padding around the text box
point.padding = 0.2 # Padding around the point
) +
labs(
x = "Actual MPG",
y = "Predicted MPG",
color = "Model",
title = "Residuals Between Actual and Predicted MPG by Model"
) +
theme_minimal()