MGMT 17300: Data Mining Lab
Predictive Modeling in R
August 01, 2024
Course Learning Milestones

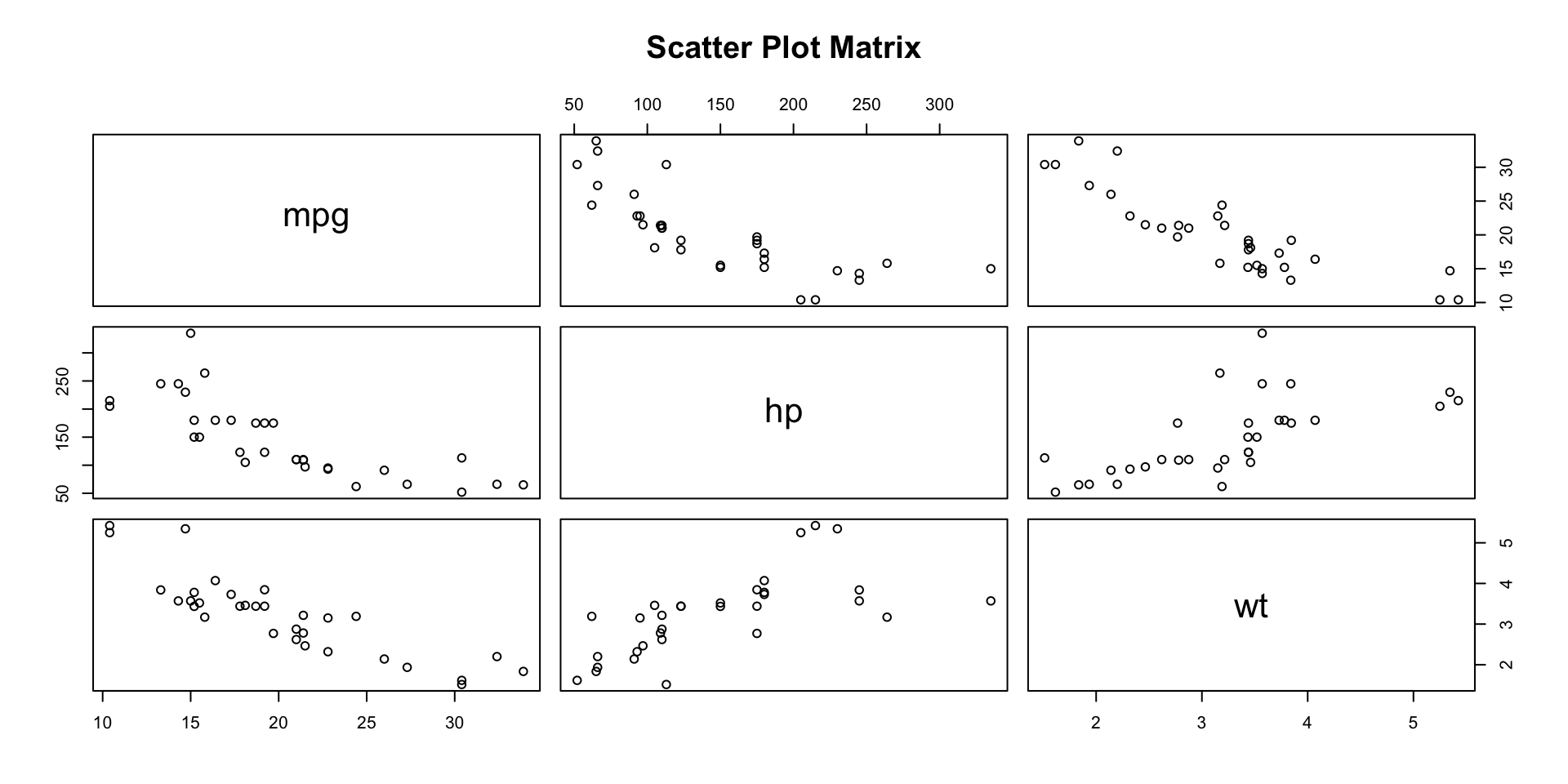
Covariance
- The Covariance is a measure of the linear association between two variables.
- Positive values indicate a positive relationship.
- Negative values indicate a negative relationship.
Correlation Coefficient

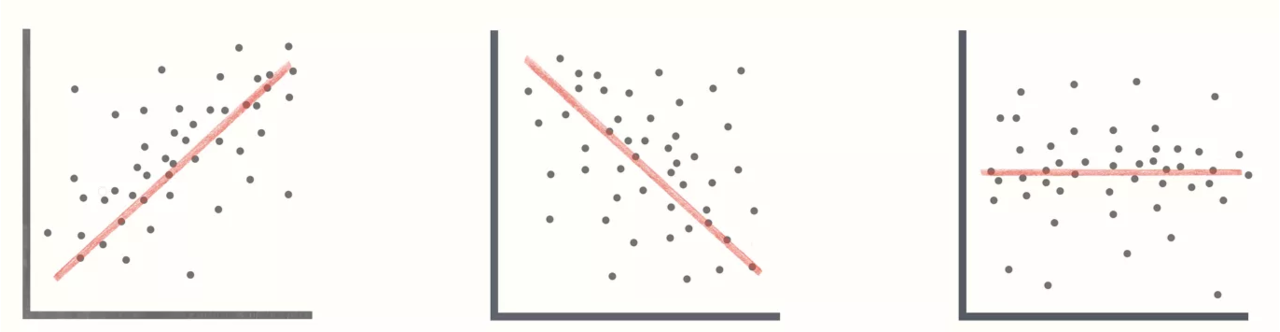
Correlation is a unit-free measure of linear association and not necessarily causation.
The coefficient can take on values between −1 and +1.
- Values near −1 indicate a strong negative linear relationship.
- Values near +1 indicate a strong positive linear relationship.
The closer the correlation is to zero, the weaker the linear relationship.
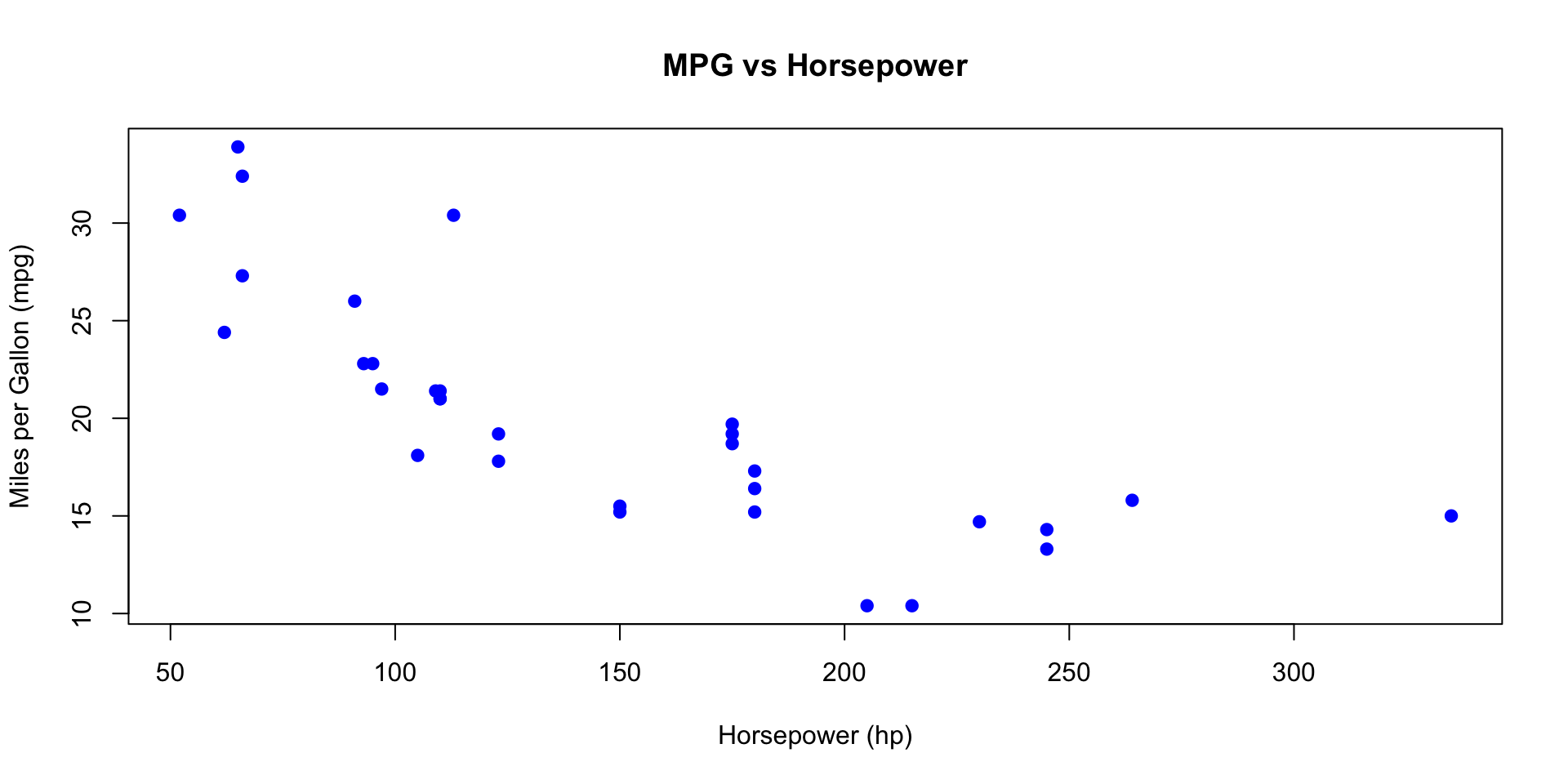
Scatter Plot of mpg vs hp
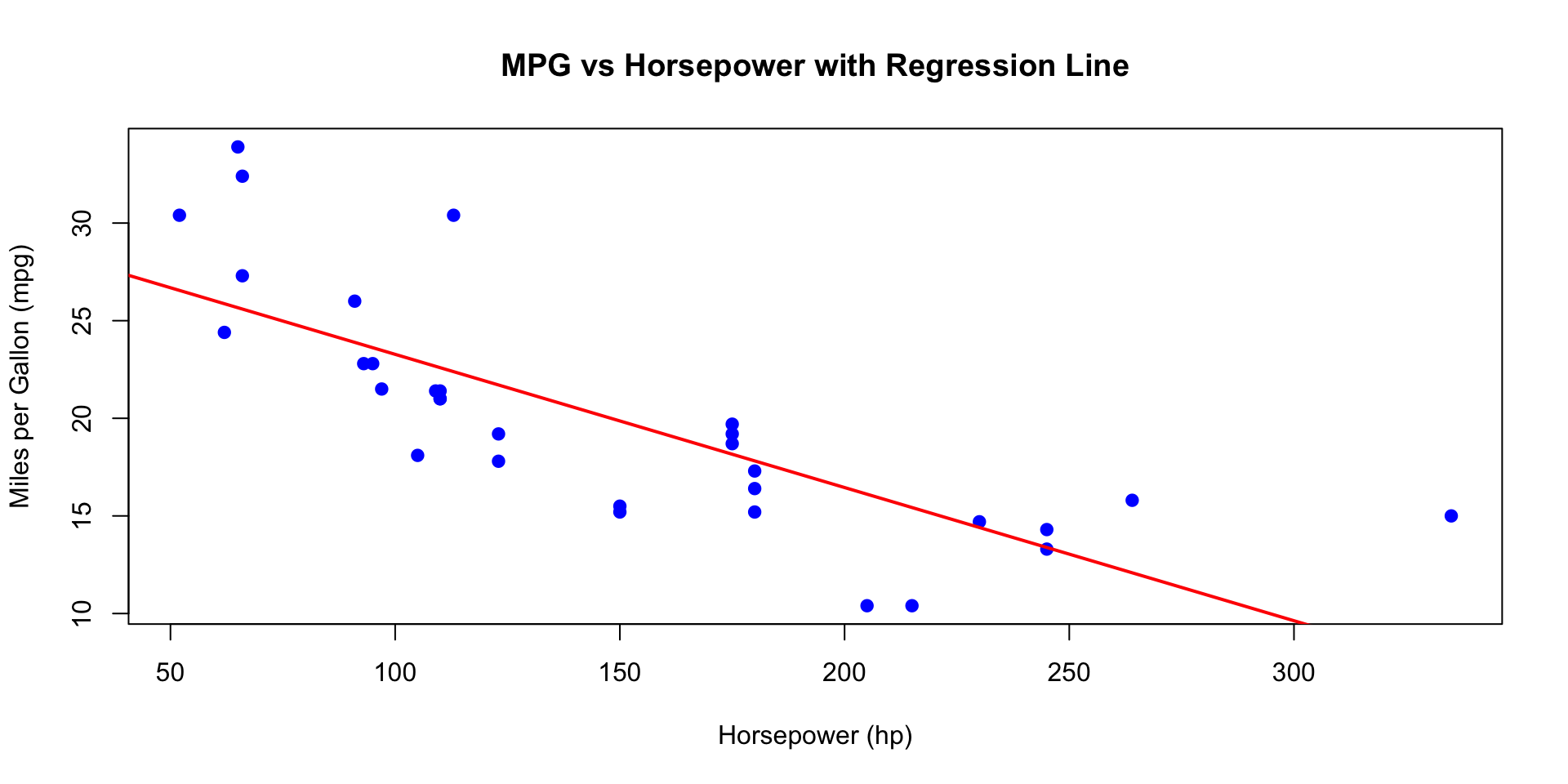
Adding the Regression Line to the Scatter Plot
Precision and Accuracy

Precision: Refers to the consistency or reliability of the model’s predictions.
Accuracy: Refers to how close the model’s predictions are to the true values.
In the context of regression:
- High Precision, Low Accuracy: Predictions are consistent but biased.
- High Precision, High Accuracy: Predictions are both consistent and valid.
- Low Precision, Low Accuracy: Predictions are neither consistent nor valid.
- Low Precision, High Accuracy: Predictions are valid on average but have high variability.
To achieve high precision and high accuracy, we need to meet the model assumptions.
Motivation: Controlling for a Variable
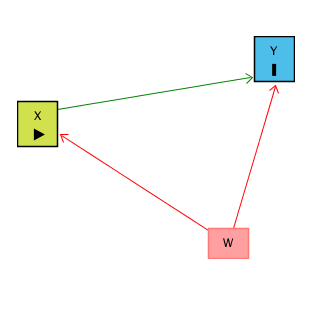
Source: Causal Inference Animated Plots
Motivation: Controlling for a Variable
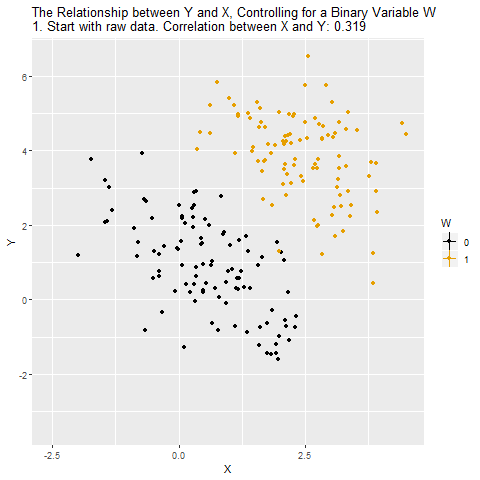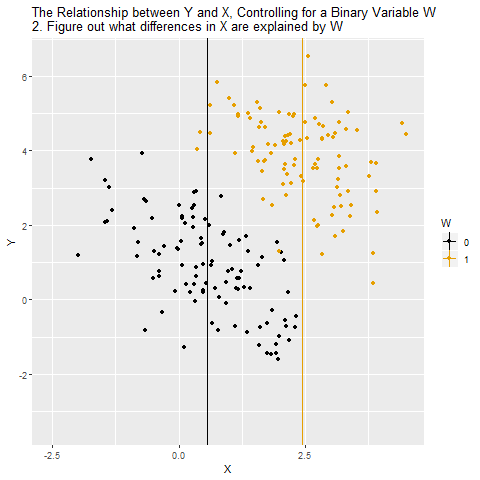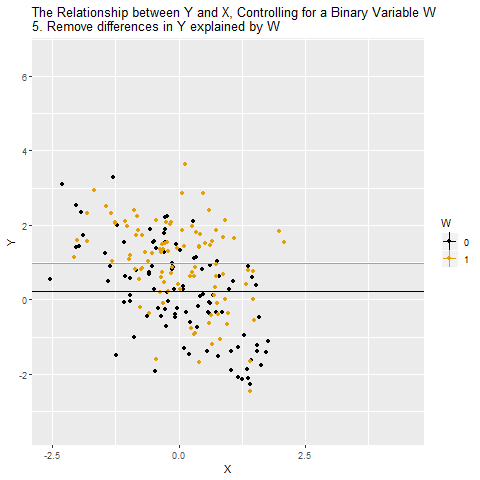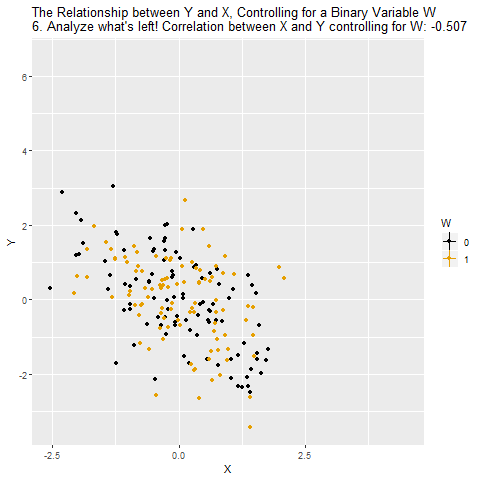
Source: Causal Inference Animated Plots