MGMT 17300: Data Mining Lab
Key Steps of Performing Data Mining in R
August 01, 2024
Overview
Lesson 06 Exercise Review
Lesson Question!
The 8 Key Steps of a Data Mining Project
Lesson 06 Exercises Review
Lesson Question!
Key Steps of a Data Mining Project
The 8 Key Steps of a Data Mining Project
- Define the project’s goal
- Acquire analysis tools
- Prepare data
- Data summarization
- Data visualization
- Data mining modeling
- Model validation
- Interpretation and implementation
Step 1: Define the project’s goal
Step 1: Define the project’s goal based on available data
The project objective serves as the guiding light.
Car Data Mining Project Example: predict a car’s fuel efficiency (measured as miles per gallon,
mpg) based on key factors or attributes of the car.
Demonstrative Project Example
Example Project: Car’s fuel efficiency (mpg) influenced by:
- Weight (wt)
- Horsepower (hp)
- Cylinders (cyl)
- Transmission type (am)
- Engine shape (vs)
The dataset becomes the mine where insights are excavated.
Step 2: Acquire Analysis Tools
Step 2: Acquire Analysis Tools
Use R for data analysis
R includes an extensive collection of packages and functions
Example R packages:
dplyrtidyr
Step 3: Prepare Data
Data preparation: transformation, cleaning, and preprocessing
Filtering out missing or invalid values
Transforming and restructuring data
Car Data Mining Project Example: Cleaning mtcars data in R using dplyr
Useful R Functions for Data Preparation
Cleaning and Filtering:
is.na(),complete.cases(),filter()
Data Transformation:
scale(),normalize(),log()
Data Restructuring:
pivot_longer(),pivot_wider()
Data Type Conversion:
as.numeric(),as.Date(),as.factor()
Step 4: Data Summarization
Summarize key insights from the core of the data to identify trends, correlations, and high-level patterns
Techniques:
- Aggregation
- Statistical summaries (mean, median, standard deviation)
- Group-by operations
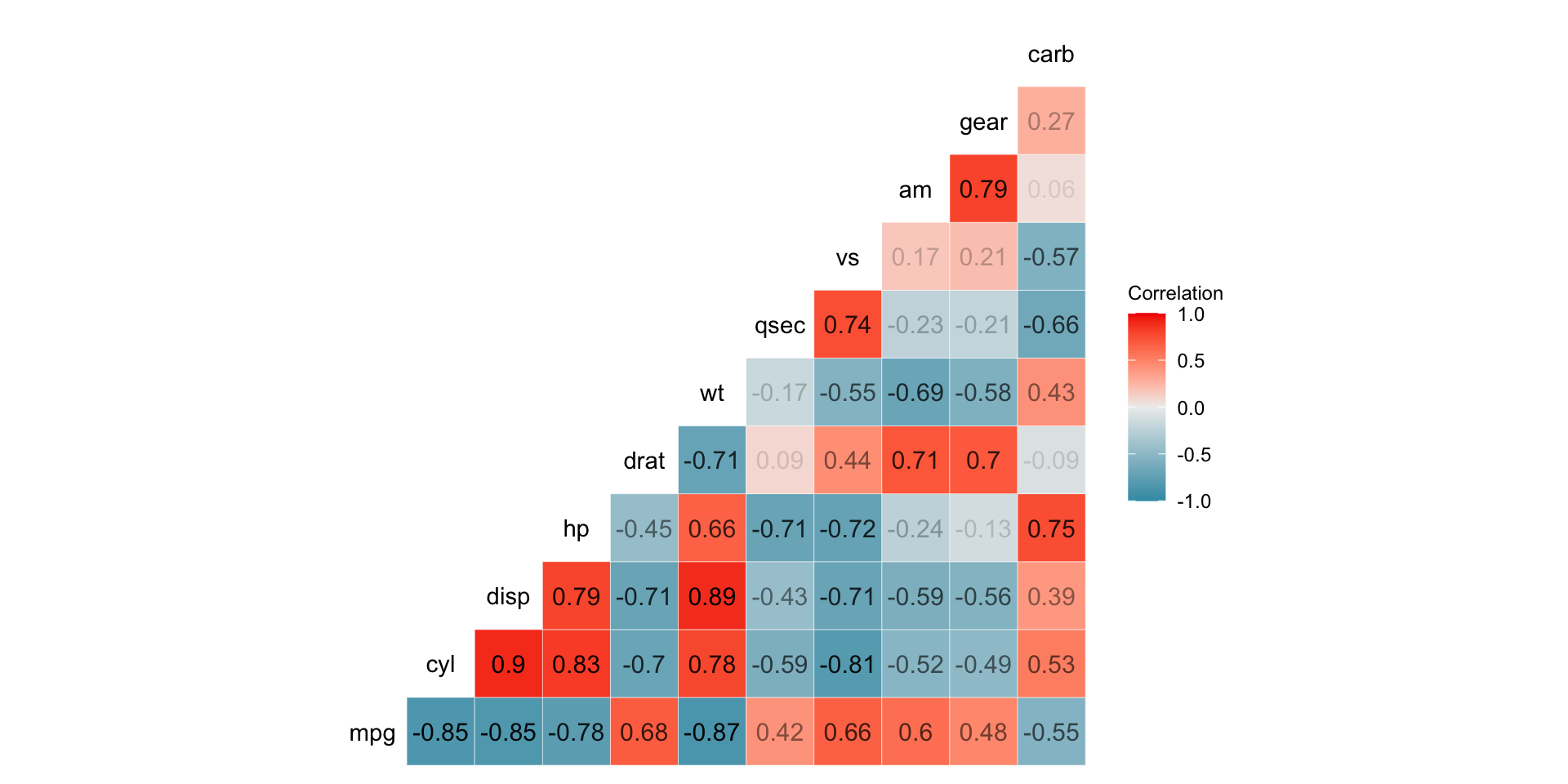
Step 5: Data Visualization
Visual representation of data is crucial for interpretation. It is used to communicate insights visually, identify relationships, and detect outliers.
Techniques:
- Histograms
- Box plots
- Scatter plots
- Bar charts
Step 5: Data Visualization
Step 6: Data Mining Modeling
Build models to uncover hidden patterns and relationships
Common techniques:
- Clustering: Groups similar data points together
- Regression: Predicts relationships between variables
Step 6: Data Mining Modeling Example Explanation
Linear Model (
lm):- Fits a linear regression model to predict
mpgusingwt(weight) andhp(horsepower).
- Fits a linear regression model to predict
summary(model):- Provides detailed output of the model’s performance.
Model Output:
Intercept: 37.23 (baseline
mpgwhenwtandhpare zero).Coefficients:
- For every unit increase in
wt,mpgdecreases by 3.88 units. - For every unit increase in
hp,mpgdecreases by 0.03 units.
- For every unit increase in
R-squared:
- Multiple R-squared: 0.8268 (explains \(\approx83%\) of variance in
mpg). - Adjusted R-squared: 0.8148 (adjusts for number of predictors).
- Multiple R-squared: 0.8268 (explains \(\approx83%\) of variance in
Significance:
- Both
wtandhpare significant predictors (p-values < 0.05).
- Both
Step 7: Data Mining Model Validation
Validate model accuracy and generalizability to ensure that the model performs well on unseen data and avoids overfitting.
Techniques:
- Cross-validation
- Training/Test split
- Performance metrics (e.g., R-squared, Precision, Recall)
Step 7: Model Validation Example Explanation
Cross-validation:
trainControl(method = "cv", number = 10)sets up 10-fold cross-validation.- The model is trained on 9 parts of the data and tested on the remaining part, iterating 10 times.
train() function:
- Trains a linear regression model (
lm) usingwt(weight) andhp(horsepower) as independent variables to predictmpg.
- Trains a linear regression model (
Model Output:
- RMSE (Root Mean Squared Error): 2.48 (average error in prediction). It tells us how concentrated the data points are around the line of best fit.
- R-squared: 0.94521 (approximately 94.5% of variability in
mpgexplained by the model). - MAE (Mean Absolute Error): 2.23 (average magnitude of prediction error). Lower MAE values indicate better model performance. On average, the model’s prediction of mpg differs from the actual value by about 2.23 mpg.
Purpose:
- Ensures the model generalizes well by preventing overfitting.
- Provides reliable performance metrics for real-world application.
Step 8: Interpretation and Implementation
Interpret results and apply findings in decision-making
Key considerations:
- How can the insights be used in practice?
- Are the patterns meaningful for the project’s goals?
Implementation:
- Integrate findings into business strategy or decision-making processes
- Examples: Customer segmentation, risk management, optimization
Summary
Summary
Main Takeaways from this lecture:
8 Key Steps of Data Mining:
- Defining the project’s goal is crucial to guide the process.
- Using appropriate analysis tools, such as R, is essential for data mining.
Data Preparation:
- Cleaning, transforming, and restructuring the data is critical for accurate results.
- R packages like
dplyrandtidyrstreamline these tasks.
Modeling:
- Linear regression helps uncover relationships between variables (e.g., predicting
mpgfromwtandhp).
- Linear regression helps uncover relationships between variables (e.g., predicting
Model Validation:
- Validate models to ensure generalizability (e.g. through cross-validation techniques).
Interpretation & Implementation:
- Applying insights from the model to real-world decision-making, such as business strategy or optimization.
Thank you!
Data Mining Lab